Zero-Copy Streams and Scatter/Gather I/O
Zero-copy stream work pays off only when you know exactly which copy you are avoiding. A stream pipeline can be correct and still waste CPU by moving bytes through layers that never inspect them.
The hard part is being precise about the mechanism in use. Kernel zero-copy, copy-on-write file clones, Buffer views, and vectored writes all remove different work. If you group them under one label, it becomes easy to make the wrong performance call.
Zero-Copy Stream Patterns
Zero-copy I/O means the data path avoids a copy that a normal read or write path would have made. For stream code, start with two checks. First, ask whether bytes are copied between kernel space and user space. Then ask whether JavaScript creates another copy inside the process.
Kernel space is the protected memory and execution context owned by the operating system. User space is where your Node.js process runs. A normal read copies bytes from a kernel buffer into a user-space Buffer. A normal write copies bytes from that Buffer back into the kernel. Those copies are needed when JavaScript has to parse, compress, encrypt, validate, or rewrite the data. They are wasted when the process only forwards bytes unchanged.
DMA, or Direct Memory Access, is the hardware side of this path. A device can transfer bytes to or from memory after the kernel sets up the operation. The CPU still does plenty of work. It enters syscalls, manages descriptors, handles page-cache state, runs protocol code, and receives interrupts. The win is more specific - fewer payload bytes move through user-space memory, and the CPU cache is less affected by bytes JavaScript never reads.
Scatter/gather I/O often comes up in the same discussion, but it solves a different problem. It passes several memory ranges to one I/O operation. For writing, writev() gathers bytes from multiple buffers and writes them in order. For reading, readv() scatters incoming bytes across several buffers. This can reduce syscall count and avoid building one temporary Buffer with Buffer.concat().
Each mechanism removes a different kind of work -
| Mechanism | Copy avoided | Contract |
|---|---|---|
Buffer.subarray() | JavaScript Buffer copy | The view shares memory with the original Buffer. |
Buffer.from(view) | None | The new Buffer owns an independent copy. |
FileHandle.writev() | User-space concatenation | Buffers must stay valid until the write finishes. |
Writable _writev() | Repeated stream writes | The destination must consume a batch safely. |
fs.copyFile() with COPYFILE_FICLONE | File data duplication, when supported | Node requests a copy-on-write reflink and may fall back. |
sendfile() | User-space transfer between file descriptors | Platform, descriptor type, protocol, and TLS path decide availability. |
This is why "zero-copy" needs careful wording. A Buffer view avoids a copy inside the process. A reflink asks the filesystem for copy-on-write file duplication. writev() still moves user memory to the kernel, but it avoids joining buffers first. A sendfile() path can keep file payload bytes out of user space, but the public stream API is still a stream API with JavaScript-visible buffering.
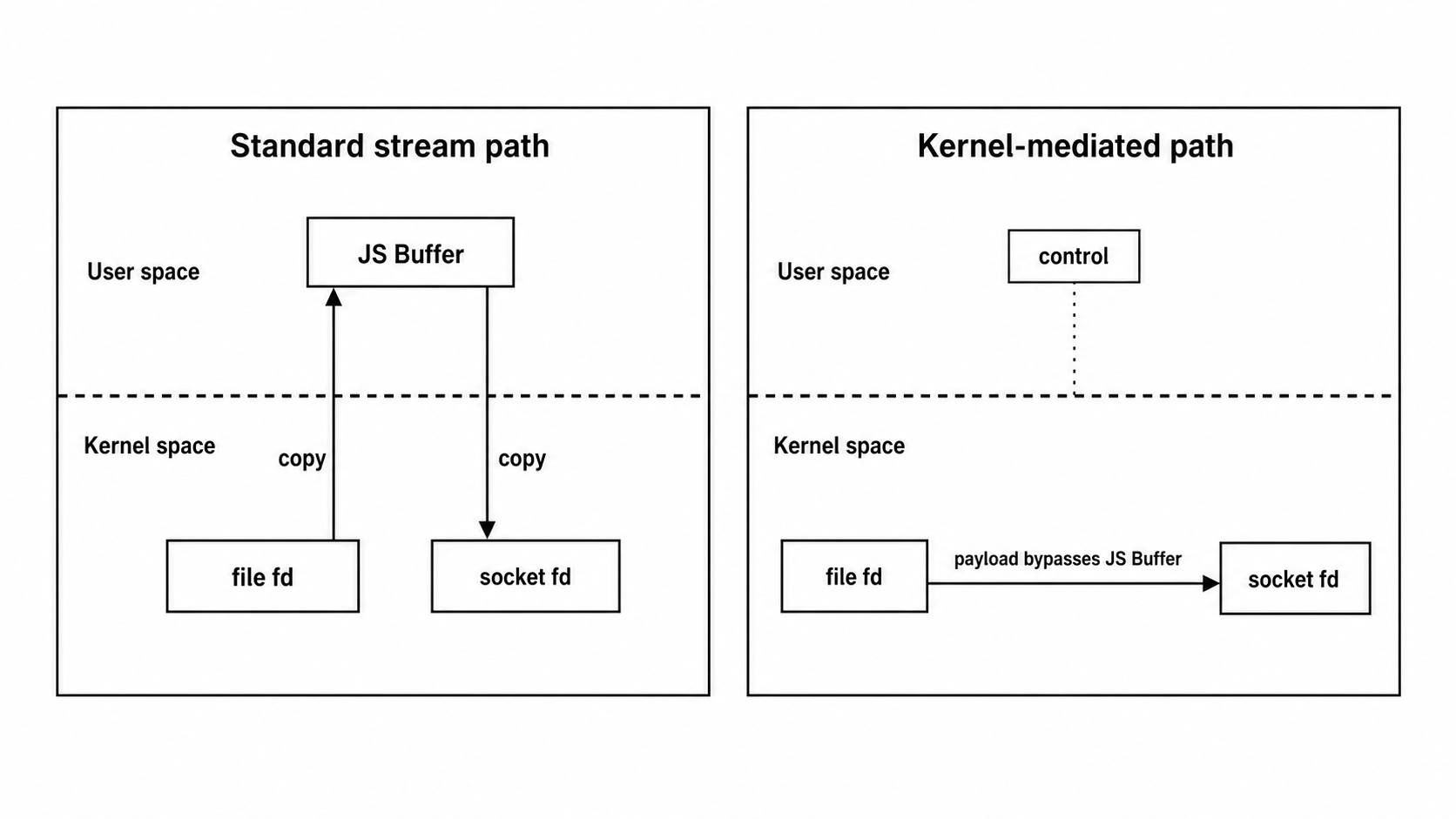
Figure 3.1 - A normal stream path reads chunks into JavaScript-visible Buffers before writing them onward. Kernel-mediated transfer paths, when available, keep unchanged payload bytes out of user space.
The Standard Stream Path Uses Buffers
A common file-serving shape looks small -
import { createReadStream } from "node:fs";
createReadStream("video.mp4").pipe(socket);In the standard fs.ReadStream to net.Socket path, Node reads file chunks into Buffers and writes those chunks to the socket. pipe() wires stream flow control and backpressure. It does not turn this pair into a public sendfile() call.
On Linux, a syscall trace of this path in Node v24 shows socket write() calls for the emitted chunks. The test in this repository used a 128 KiB file and observed two 64 KiB socket writes, with no sendfile() call in the traced process. That is an observation of the standard stream path on this platform. It is not a promise about every native path Node core may use internally.
The lower-level OS primitive has tighter rules. Linux sendfile() copies between file descriptors inside the kernel. Its input descriptor must support mmap()-like operations, and the output descriptor rules changed across Linux versions. Other operating systems expose similar ideas through different APIs and semantics. Portable stream code cannot treat sendfile() as a universal replacement for read() plus write().
TLS narrows the path further. A traditional TLS send path encrypts bytes before they reach the socket. Node's public HTTPS and HTTP/2 APIs do not expose a general "send this file through kernel TLS without user-space payload handling" contract. If an edge server needs that behavior, benchmark specialized servers and platform features instead of assuming a stream pipeline will use that path.
Node does expose file-copy paths that can avoid user-space payload copies -
import { constants } from "node:fs";
import { copyFile } from "node:fs/promises";
await copyFile(src, dest, constants.COPYFILE_FICLONE);COPYFILE_FICLONE asks the filesystem for a copy-on-write reflink. If the platform or filesystem cannot create that clone, Node may fall back to another copy mechanism. On the local Linux verification run for this chapter, copyFile() attempted FICLONE, received EOPNOTSUPP, and then used copy_file_range().
Use the force flag when fallback would break the promise your tool is making -
await copyFile(src, dest, constants.COPYFILE_FICLONE_FORCE);With COPYFILE_FICLONE_FORCE, failure to create the reflink becomes an error. Use that behavior for tools that promise near-instant snapshots or space-efficient duplication. Plain COPYFILE_FICLONE means "try the clone first."
http2stream.respondWithFile() sits in a different bucket. It is a documented HTTP/2 convenience for sending a file response, with options such as offset, length, statCheck, and onError. The docs describe the API contract. They do not promise a portable zero-copy send path.
Memory Mapping Is Separate
Memory mapping maps file pages into a process address space. That puts it beside streams, not inside the normal stream contract. Node core does not provide a built-in JavaScript mmap() API. Native addons can expose one, but then the application owns platform differences, mapping flags, page-fault behavior, lifetime, and crash risk from invalid memory access in native code.
Mapping behavior depends on the flags. A writable shared mapping can reflect changes back to the file. A private mapping uses copy-on-write behavior. Read-only mappings have their own rules. Treating every memory map as "file bytes that update the file" will lead to wrong behavior.
For sequential stream processing, fs.createReadStream(), FileHandle.read(), and pipeline() are usually the right level. They fit Node's backpressure model and failure handling. Memory mapping belongs to random-access workloads where page-level behavior is part of the design, not to ordinary stream pipelines.
Buffer Views Need Ownership Discipline
Most copy bugs in stream code happen at the application Buffer level. Kernel zero-copy will not help if a transform keeps concatenating chunks that it could process separately.
Buffer.subarray() creates a view -
const header = chunk.subarray(0, 16);
const body = chunk.subarray(16);No payload bytes move here. header and body reference the same underlying allocation as chunk. If you mutate a shared byte through one view, the other views observe that change. The same shared allocation also affects lifetime. Retaining a tiny view can keep a much larger backing allocation reachable.
Use a copy when the data must outlive the source Buffer's ownership window -
const frame = chunk.subarray(start, end);
queue.push(Buffer.from(frame));Buffer.from(frame) allocates new storage and copies the selected bytes. That cost is reasonable when the original Buffer may be reused, mutated, or much larger than the frame you plan to keep.
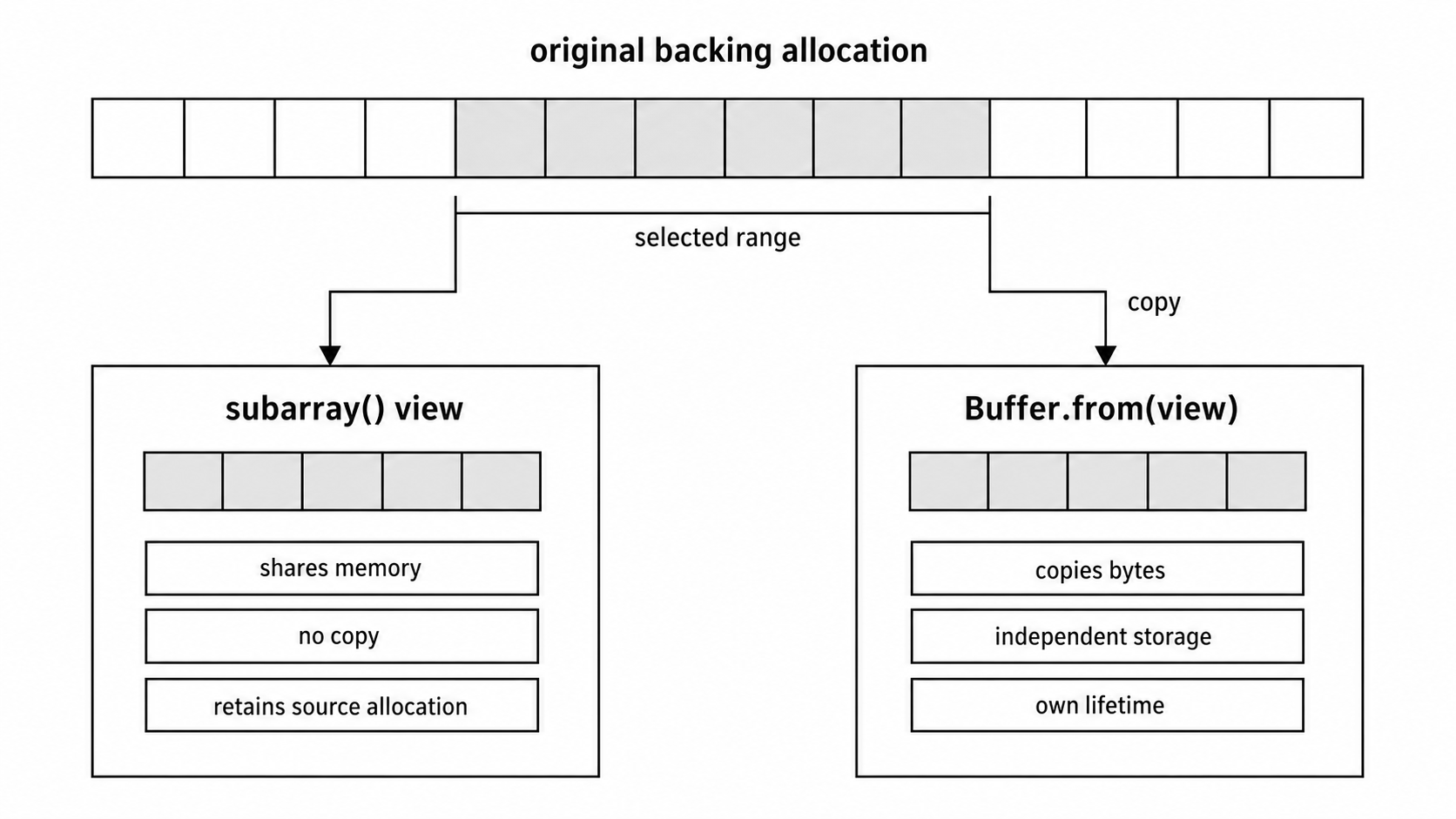
Figure 3.2 - A view avoids copying but keeps the original backing allocation and mutation rules. A copy pays for byte movement so the retained frame has its own lifetime.
Buffer.slice() needs precise wording. In Node v24, Buffer.prototype.slice() still returns a view over the same memory, matching legacy Buffer behavior. Current Node v24 did not emit a runtime deprecation warning in local checks, even with pending and trace deprecation flags. Prefer subarray() because it clearly means "view" across Buffers and TypedArrays. Do not teach a runtime warning that the runtime does not emit.
Buffer length is fixed. JavaScript does not reallocate an existing Buffer in place and invalidate existing views by changing its length. The real hazards are shared mutation and retention. If a parser keeps chunk.subarray(0, 8) from a 64 KiB read chunk in a long-lived cache, that small header view can keep the whole 64 KiB allocation reachable.
The most common accidental copy is still Buffer.concat() -
const chunks = [];
for await (const chunk of source) chunks.push(chunk);
const all = Buffer.concat(chunks);Sometimes that copy is required. A decompressor, parser, or signature verifier may need one continuous byte range. Many stream transforms can process each chunk or parsed frame independently. In those cases, concatenation changes bounded streaming memory into full-payload memory.
String conversion has the same shape -
const text = chunk.toString("utf8");
const out = Buffer.from(text.toUpperCase());This code decodes bytes into a JavaScript string, allocates transformed string data, and then encodes a new Buffer. Use that path when the operation is actually text. Keep the data as bytes when the operation is byte-oriented. buffer.indexOf(), subarray(), and small state machines often avoid the round trip.
Scatter/Gather I/O
Scatter/gather I/O helps when the data is already split into separate pieces. A protocol response might have a header, a payload, and a trailer. A file record might have a fixed-size prefix and a variable body.
Concatenating those buffers into one Buffer creates a temporary allocation and copies payload bytes. Writing them one at a time creates several I/O calls. Vectored I/O keeps the buffers separate in user space and hands the ordered list to the kernel.
Node exposes this at the file API level -
import { open } from "node:fs/promises";
const file = await open("out.bin", "w");
try {
await file.writev([header, payload, trailer]);
} finally {
await file.close();
}FileHandle.writev() passes the buffers as an ordered list. The kernel writes buffer 0, then buffer 1, then buffer 2. The local verification script wrote "hello " and "world" through writev() and read back "hello world" through readv(), confirming the ordering in Node v24.
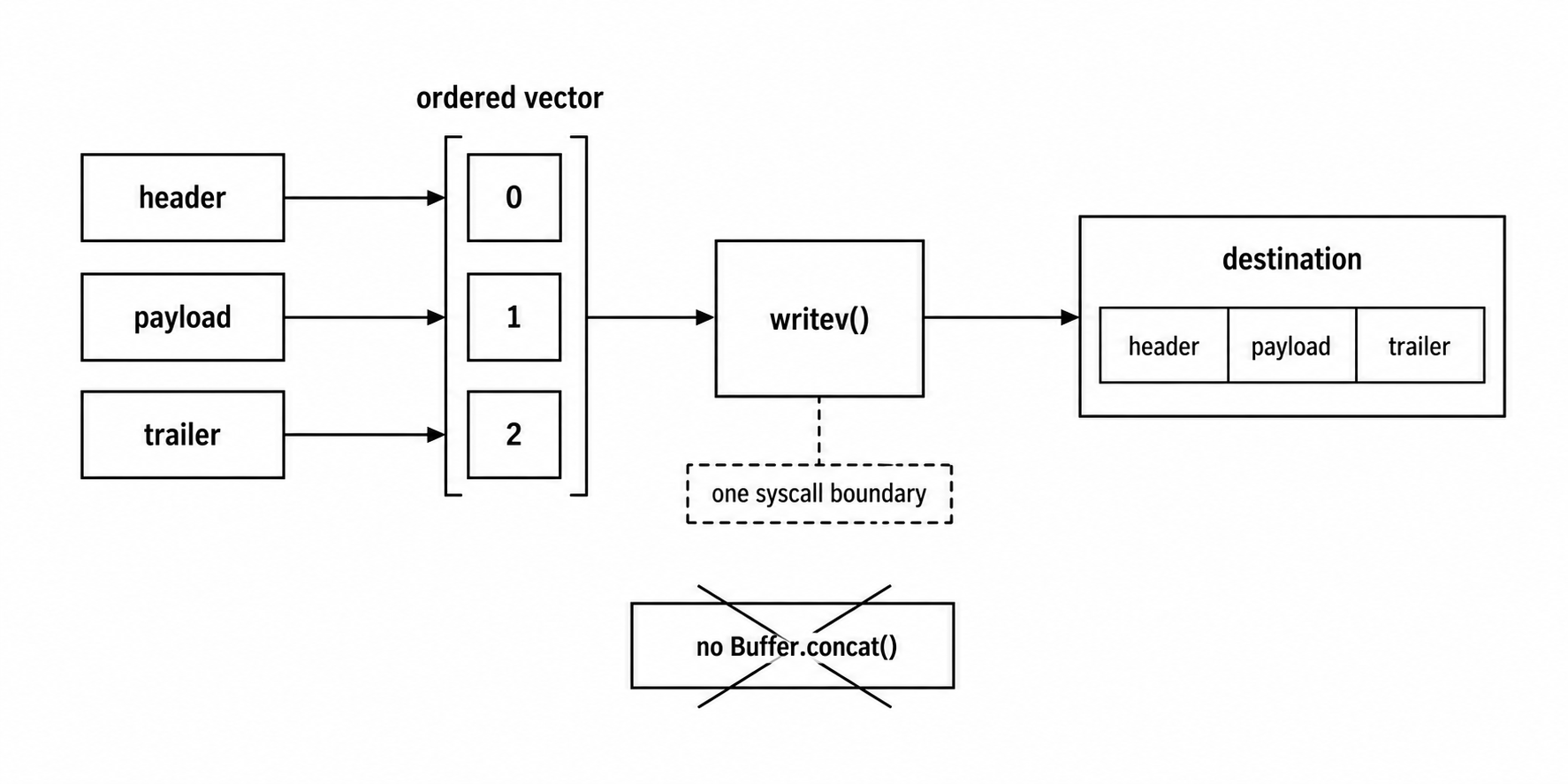
Figure 3.3 - writev() preserves separate user-space buffers while handing the destination one ordered vector. The win is avoiding a temporary concatenation when the destination can consume the vector directly.
The buffers passed to writev() must remain stable until the promise resolves or the callback fires. If an application reuses a pooled buffer before the write completes, the kernel may write the new bytes instead of the original bytes. JavaScript memory safety prevents a native crash here, but it does not protect the protocol from corrupted output.
Partial writes add another ownership handoff. A write operation can report fewer bytes than requested, especially against nonblocking descriptors and sockets. High-level Node file APIs hide some retry behavior, but low-level code and native addons must account for short writes. If correctness depends on the write result, check bytesWritten and keep enough state to retry the unwritten suffix. Retry logic is more involved with a vector because the remaining range may start in the middle of one Buffer and continue through later Buffers.
Writable streams expose a related hook named _writev(). This hook is stream implementer machinery. It is separate from fs.writev() and FileHandle.writev(). When a Writable has several buffered chunks and implements _writev(), Node can pass the pending items to _writev() as an array shaped like { chunk, encoding }.
A custom destination can use that shape like this -
class FramedSink extends Writable {
_write(chunk, _enc, cb) { writeOne(chunk).then(() => cb(), cb); }
_writev(items, cb) {
const chunks = items.map(({ chunk }) => chunk);
writeBatch(chunks).then(() => cb(), cb);
}
}writeBatch() might call FileHandle.writev(), a database batch API, or a protocol encoder that can consume separate chunks. If it calls Buffer.concat() and then writes one Buffer, the implementation is batching by concatenation rather than true gather I/O. That trade can still win for many tiny chunks, but it exchanges syscall count for a copy. Say that plainly in code comments and documentation.
Implement _writev() when profiling shows many buffered small writes and the destination can consume a batch safely. It is not a universal upgrade. A destination that already batches internally may gain nothing. A destination that requires strict per-message acknowledgements may become harder to reason about. A _writev() implementation that ignores lifecycle, partial writes, backpressure, or errors can be worse than a plain _write().
Corking and Flush Points
cork() holds Writable chunks in the stream's internal buffer, and uncork() releases them. If _writev() exists and several chunks are pending, the flush can enter _writev() as one batch. Without _writev(), Node drains the buffered chunks through _write() calls.
The safe application pattern keeps the calls close together -
writable.cork();
try {
writable.write(header);
writable.write(payload);
} finally {
process.nextTick(() => writable.uncork());
}Deferring uncork() to process.nextTick() lets other writes from the same turn join the batch. The finally block prevents the stream from staying corked if code between the calls throws.
Nested corking uses a counter. Two cork() calls require two uncork() calls before data flushes -
writable.cork();
writable.cork();
writable.write("x");
writable.uncork();
writable.uncork();After the first uncork(), the stream is still corked. The final uncork() releases the buffered write. The local verification script confirmed that Node v24 kept the batch untouched after the first uncork and flushed after the second.
One reviewed batching pattern had a serious bug. It corked the stream, wrote a chunk, and waited for the write callback to call uncork(). That callback cannot fire while the write is still behind the corked buffer. The stream stays corked, and pending writes stay pending.
Uncork from a point that does not depend on the corked write callback. Use an explicit batch point, process.nextTick(), setImmediate(), or a short timer. Timer-based batching also needs cleanup on finish, close, and error, because a pending timer can later try to uncork a stream that has already ended.
Corking adds latency because bytes sit in memory until the flush point. Use it around bursts with an endpoint you control - a response header plus body prefix, a batch of encoded frames, or a small group of records. Avoid corking a long-running stream for its whole lifetime.
Buffer Pooling Without Lying About Copies
Buffer pooling reduces allocation churn when the application owns the buffer lifetime. It does not remove incoming stream chunks that were already allocated. If a Readable has already allocated a chunk and the application copies that chunk into a reusable buffer, the pool added a copy. Pooling helps when it replaces an allocation the application otherwise controlled.
A minimal pool needs size validation and a maximum retained count -
class BufferPool {
constructor(size, max = 32) { this.size = size; this.max = max; this.free = []; }
acquire() { return this.free.pop() ?? Buffer.allocUnsafe(this.size); }
release(buf) {
if (buf.length !== this.size || this.free.length >= this.max) return;
this.free.push(buf);
}
}Buffer.allocUnsafe() skips zero-fill. Every byte that another part of the program can observe must be overwritten before release or before exposure. For sensitive data, wipe the buffer before returning it to the pool -
buf.fill(0);
pool.release(buf);The hard part is release timing. A pooled Buffer can be reused only after every consumer has finished with every view over it. Pushing buffer.subarray(0, n) downstream and immediately returning buffer to the pool is unsafe. Downstream reads may observe later writes into the same allocation.
Copying before release is safe -
const view = buffer.subarray(0, bytesRead);
this.push(Buffer.from(view));
pool.release(buffer);This pattern is lifetime-safe, but it is not zero-copy. The pool owns the temporary read buffer, and the pushed Buffer owns a copy sized to the actual data. That compromise often fits custom sources because it bounds scratch allocations without corrupting downstream data.
Pooling pays off only when allocation shows up in the profile. Node already has internal Buffer pooling behavior for some small unsafe allocations, and V8 tracks Buffer wrappers separately from the external backing memory. A hand-rolled pool can increase RSS, retain stale data, and make ownership harder to follow. Keep it small, uniform, and local to code that controls both acquisition and release.
High-Water Marks and Batch Size
highWaterMark is a threshold, not a hard memory cap. For byte-mode streams in Node v24, the default threshold is 64 KiB. Object mode defaults to 16 objects. Node v22 changed the byte-mode default from the older 16 KiB value.
You can check the runtime directly -
import { getDefaultHighWaterMark } from "node:stream";
console.log(getDefaultHighWaterMark(false)); // 65536
console.log(getDefaultHighWaterMark(true)); // 16In Node v24.15, base Readable, base Writable, fs.createReadStream(), and fs.createWriteStream() all reported 64 KiB for byte streams in the local verification run. Specific stream implementations can still choose their own defaults, so read the API docs or inspect readableHighWaterMark and writableHighWaterMark when a tuning decision depends on the value.
Raising highWaterMark can reduce pause/resume churn and increase batch size. It also increases peak memory per stream. Ten thousand streams with an extra 64 KiB each create a very different process from ten streams with that setting. Tune it next to concurrency limits, not in isolated examples.
Measuring Copy and Syscall Costs
Exact performance numbers belong to the workload being tested. Syscall cost, memory bandwidth, SSD behavior, GC time, and writev() benefit depend on CPU, kernel, filesystem, storage, network, chunk size, concurrency, and Node version. Precise unsourced percentages make a chapter age badly.
Start by checking the syscall shape. On Linux -
strace -f -e write,writev node server.jsIf a batching change still emits one write() per tiny chunk, _writev() is not on the hot path or the stream is flushing before chunks accumulate. If writev() appears with many buffers per call, the batching mechanism is active. strace may require ptrace permissions in containers and locked-down production hosts, so run it in a controlled environment.
For file-copy path checks -
strace -f -e ioctl,copy_file_range,sendfile node copy.jsThe trace can show whether a reflink was attempted, whether copy_file_range() was used, or whether the path fell back. The result is filesystem-specific. A Btrfs volume and a temporary filesystem can produce different traces from the same JavaScript.
CPU profiling tells you whether copies are worth chasing -
node --prof app.js
node --prof-process isolate-*.logLook for time in Buffer operations, encoding, transform functions, and native copy routines. For allocation pressure, combine process.memoryUsage(), heap profiles, and GC tracing -
node --trace-gc app.jsThe useful profile matches production - real chunk sizes, real concurrency, real transforms, and realistic destinations. A microbenchmark that writes tiny buffers to /dev/null can prove a mechanism works. It cannot prove the pipeline needs it.
Choosing the Mechanism
Use Buffer views when parsing or framing data inside the current ownership window. Copy when a view must outlive that window.
Use FileHandle.writev() or a real vectored destination when the data is already split into buffers and the destination can consume them in order. Avoid Buffer.concat() unless a continuous Buffer is required or measurement shows that one copy plus one write beats many writes.
Use _writev() for custom Writable streams that regularly receive buffered small chunks. Keep _write() correct first. _writev() is an optimization hook, not a replacement for the normal Writable contract.
Use cork() when the code has a clear burst point. Uncork from that point, not from a callback that cannot fire until uncorking happens.
Use fs.copyFile() for file-to-file duplication when JavaScript does not need the bytes. Choose COPYFILE_FICLONE_FORCE when a copy-on-write clone is part of the contract.
Leave memory mapping to code that really needs mapped random access and can handle the native-platform risk.
The fastest stream code usually starts plain and gets optimized after profiling. It preserves backpressure, avoids accidental retention, writes chunks in the shape the destination accepts, and keeps ownership rules visible anywhere bytes leave the current function.