Stream Pipelines: Error Propagation, Cleanup, and Cancellation
Stream pipelines connect several stream stages into one data path. Moving chunks is only the visible part. The harder part is keeping the whole chain in a valid state when one stage fails, closes early, applies backpressure, or leaves a resource open while another stage still has buffered data.
source.pipe(dest) connects data flow and backpressure between two streams. stream.pipeline() goes further. It gives the whole chain one success or failure path, then handles cleanup when the operation cannot continue.
Stream Pipeline Error Handling
The earlier stream chapters treated Readable, Writable, and Transform streams as individual objects. That model is still needed because each stream has its own buffer, backpressure rules, and event lifecycle.
Real applications usually combine those objects. At that point, the question changes from "does this stream work?" to "what happens to the whole data path when one part changes state?"
That is where pipeline() becomes useful. Use it when one failure should stop the full chain. It destroys streams as needed and reports the result through a callback or promise.
finished() has a narrower job. It watches one stream until that stream completes or fails. Modern pipelines can also include async generator stages and accept an AbortSignal for cancellation.
A production stream chain is not done just because bytes reached the destination. It is done when backpressure was respected, errors reached the operation result, and resources either completed normally or were torn down intentionally.
The pipe() Method
pipe() connects a Readable stream to a Writable stream and automatically manages flow so a faster source does not overwhelm a slower destination. The Writable Streams chapter covered that pressure path in detail. Here, we care about what happens around that path once the chain grows.
Because pipe() returns the destination stream, you can build a chain with repeated calls -
readable.pipe(transform1).pipe(transform2).pipe(writable);This creates a four-stage pipeline - readable -> transform1 -> transform2 -> writable. Data moves forward through each stage, while backpressure travels backward from the final writable toward the original readable.
Compressing a log file uses the same shape -
import { createReadStream, createWriteStream } from "node:fs";
import { createGzip } from "node:zlib";
createReadStream("app.log")
.pipe(createGzip())
.pipe(createWriteStream("app.log.gz"));Three streams are involved. The file reader produces chunks, the gzip transform compresses them, and the file writer saves the compressed data. Memory use stays bounded as long as each stage respects the backpressure signal from the next stage.
The weakness appears when the chain does not finish normally. When a piped stream fails, the stream that hit the problem emits an error event. That error belongs to that stream. As the Readable and Writable chapters showed, an unhandled stream error can crash the process, so every stage needs attention -
const reader = createReadStream("input.txt");
const transform = createGzip();
const writer = createWriteStream("output.gz");
reader.pipe(transform).pipe(writer);
function logStreamError(err) {
console.error("Stream error:", err);
}
reader.on("error", logStreamError);
transform.on("error", logStreamError);
writer.on("error", logStreamError);Even in this small example, the problem is easy to see. The application has to remember every stream in the chain. Miss one error listener and that failure path is not handled.
Seeing the error is only half of the issue. When an error happens in the middle of a chain built with pipe(), Node does not automatically tear down every other stream in the chain. If a transform errors, the upstream readable is unpiped from that transform, but other stages can still be left in a half-failed state. The destination may wait for data that will never arrive, and resources owned by other stages are still your responsibility.
That is how dangling resources show up. File handles remain open, network connections are not cleaned up, and buffered work sits inside objects that no longer have a useful data path. Manual cleanup means destroying the whole group when any member fails -
function onError(err) {
reader.destroy();
transform.destroy();
writer.destroy();
console.error("Pipeline failed:", err);
}
reader.on("error", onError);
transform.on("error", onError);
writer.on("error", onError);This is still fragile. If you add a new stream to the pipeline, you must remember to register it and destroy it from the same failure path. The larger the chain becomes, the easier it is for cleanup code to fall out of sync with the actual stream graph.
Completion has a similar problem. The readable emits end when it is done reading. The writable emits finish when it is done writing. Transforms have both readable and writable sides, so a multi-stage chain creates several possible events. Usually, only one of them represents the operation result you actually care about. You have to track the right event on the right stream, and that answer changes when the pipeline shape changes.
For a simple connection between two streams, pipe() is often enough. Once a chain has several stages, a real failure policy, and resources that must be cleaned up together, one owner should coordinate the lifecycle. That is the role of stream.pipeline().
The unpipe() Method
Before moving to pipeline(), it helps to name the inverse operation. unpipe() disconnects a readable from one or more destinations -
const writer = writable();
readable.pipe(writer);
readable.unpipe(writer);After that call, the readable stops sending data to the specified writable. Without an argument, it disconnects from all destinations -
readable.unpipe();The usual case is dynamic routing. A socket might start by writing to one destination, then redirect after enough data arrives to classify the stream -
socket.on("data", (chunk) => {
if (shouldRedirect(chunk)) {
socket.unpipe(fileWriter);
socket.pipe(differentWriter);
}
});Static pipelines rarely need this. When routing is part of the data model, a dedicated transform or router is usually easier to reason about than attaching and detaching pipe destinations during data events.
The lifecycle rule is the part to remember. unpipe() does not automatically end the destination. It removes the destination's pipe listeners from the source stream. The source stream's flowing state then depends on whether any consumers remain attached.
If all pipe destinations are removed and there are no data listeners, the readable can switch back to paused mode. If other consumers remain, data keeps flowing to them. If the old destination should close, call end() on it yourself.
stream.pipeline()
stream.pipeline() composes streams while owning the lifecycle of the chain. It was added to fix the error handling and cleanup problems that appear when pipe() is used as the only coordination mechanism.
The callback form looks like this -
import { pipeline } from "node:stream";
pipeline(readable, transform, writable, (err) => {
if (err) {
console.error("Pipeline failed:", err);
} else {
console.log("Pipeline succeeded");
}
});Instead of chaining pipe() calls yourself, you pass each stage to pipeline(), followed by a callback that runs when the chain completes or fails -
pipeline(stream1, stream2, ..., streamN, callback)That gives you three things pipe() does not provide by itself -
| Behavior | What pipeline() coordinates |
|---|---|
| Error propagation | If any stream emits an error, the chain stops and the callback receives that error. |
| Cleanup | Unfinished streams are destroyed with the failure error. |
| Completion | One callback reports success or failure for the whole operation. |
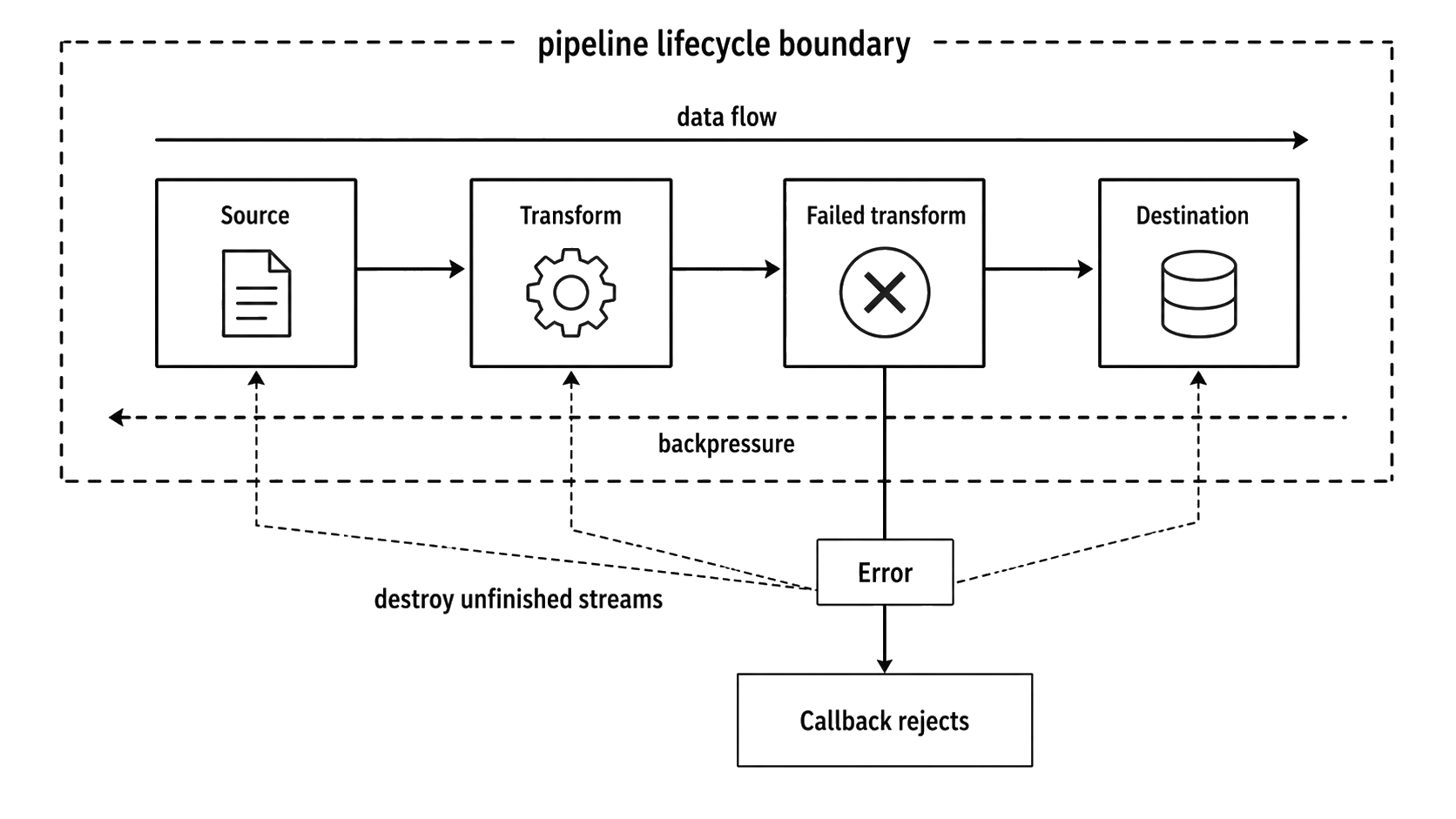
Figure 3.1 - pipeline() still uses stream flow and backpressure internally, but it gives the chain one lifecycle wrapper. A failure in one stage becomes the operation failure, and unfinished stages are torn down together.
A file-compression pipeline looks like this -
import { pipeline } from "node:stream";
import { createReadStream, createWriteStream } from "node:fs";
import { createGzip } from "node:zlib";
pipeline(
createReadStream("input.txt"),
createGzip(),
createWriteStream("output.gz"),
(err) => {
if (err) {
console.error("Compression failed:", err);
} else {
console.log("Compression succeeded");
}
}
);If any of these streams errors - the file read fails, the gzip transform encounters invalid input, or the file write hits a disk-full condition - the callback receives that error and pipeline() destroys the unfinished streams. If every stage completes normally, the callback runs with err as undefined.
That removes the scattered lifecycle code from the earlier pipe() example. There is one operation result, one completion path, and one place to decide what the application should do next.
Most modern code uses the promise-based version from stream/promises -
import { pipeline } from "node:stream/promises";
import { createReadStream, createWriteStream } from "node:fs";
import { createGzip } from "node:zlib";
try {
await pipeline(
createReadStream("input.txt"),
createGzip(),
createWriteStream("output.gz")
);
console.log("Compression succeeded");
} catch (err) {
console.error("Compression failed:", err);
}This version resolves when the pipeline completes and rejects when any stage fails. In an async function, that fits naturally with try and catch. The stream graph stays inside the operation, while the caller sees a normal promise result.
Use the callback form when the surrounding code is callback-based. Use stream/promises when the surrounding code already uses async and await.
One caveat applies when stream instances are kept alive after a pipeline call. pipeline() can leave listeners attached after the callback runs or the promise settles. That behavior protects against late errors from unusual stream implementations, but it also means a failed pipeline is not a good place to recycle stream objects. Create fresh streams for the next attempt.
HTTP responses and sockets need extra care. If a pipeline writes directly to a response and an upstream stream fails, pipeline() may destroy the response socket before the callback can send an application-level error body. Decide whether you can safely hand that socket to pipeline() while the response protocol might still need more writes.
How pipeline() Works Internally
The internals explain why a stage failure becomes a pipeline failure. When you call pipeline(s1, s2, s3, callback), the function still uses the same pipe() mechanics for data flow and backpressure. Around that flow, it adds coordination -
| Step | Coordination work |
|---|---|
| Connect | Wire adjacent stages so chunks and backpressure move through the chain. |
| Observe | Attach listeners that can detect errors, premature closes, and completion. |
| Tear down | Destroy unfinished streams when the chain has failed. |
| Report | Invoke the callback once, with either the first failure or undefined. |
The difference from manual pipe() is not a different backpressure algorithm. It is the single error path around the chain and the cleanup that follows.
A simplified sketch shows the control flow. This is not the real implementation. Modern pipeline() handles async iterables, generator stages, complex error races, once-only callback guarantees, proper stream type detection, and edge cases that userland helpers such as pump used to cover -
let settled = false;
function done(err) {
if (settled) return;
settled = true;
if (err) destroyUnfinished(streams, err);
callback(err);
}
for (let i = 0; i < streams.length - 1; i++) {
streams[i].pipe(streams[i + 1]);
}
for (const stream of streams) {
stream.on("error", done);
}Use that sketch only for orientation. It assumes the surrounding implementation has already created streams, callback, and the helper that destroys unfinished streams. The real implementation has more completion, destroy, async-iterable, and callback-once logic than a few lines can show.
One edge case is worth keeping in mind. A custom stream can emit an error after it has already been destroyed, usually because some asynchronous work completes late. pipeline() is built so the callback is invoked only once, even if multiple streams fail around the same time.
Using pipeline() with Transform Functions
pipeline() does not require every middle stage to be a Transform instance. You can pass an async generator function, and pipeline() treats it as a transform stage -
import { createReadStream, createWriteStream } from "node:fs";
import { pipeline } from "node:stream/promises";
await pipeline(
createReadStream("input.txt", { encoding: "utf8" }),
async function* (source, { signal }) {
for await (const chunk of source) {
signal.throwIfAborted();
yield chunk.toUpperCase();
}
},
createWriteStream("output.txt")
);The generator receives the previous stage as an async iterable. For each chunk from that source, it can transform the value and yield the next output chunk. The yielded values become input for the following stage.
Inline generators are useful for small transformations. When the same stage appears in more than one place, pull it into a named generator -
async function* uppercase(source, { signal }) {
for await (const chunk of source) {
signal.throwIfAborted();
yield chunk.toUpperCase();
}
}
await pipeline(
createReadStream("input.txt", { encoding: "utf8" }),
uppercase,
createWriteStream("output.txt")
);The API rule here is the async iterable interface. Do not depend on a particular internal Transform wrapper.
Multiple generator transforms can be chained. A line splitter can preserve an incomplete line between chunks, then a second stage can filter comment lines -
async function* splitLines(source, { signal }) {
let buffer = "";
for await (const chunk of source) {
signal.throwIfAborted();
buffer += chunk;
const lines = buffer.split("\n");
buffer = lines.pop();
for (const line of lines) {
yield line + "\n";
}
}
if (buffer) yield buffer;
}The filter stage is another generator -
async function* removeComments(source, { signal }) {
for await (const line of source) {
signal.throwIfAborted();
if (!line.startsWith("#")) yield line;
}
}The pipeline then connects those functions like any other stages -
await pipeline(
createReadStream("log.txt", { encoding: "utf8" }),
splitLines,
removeComments,
createWriteStream("filtered.txt")
);Passing { encoding: "utf8" } to createReadStream() is needed here because Node's decoder handles multibyte characters that may be split across byte chunks before the generator sees them.
For simple transformations, generator stages are often enough. For more complex stateful transforms, a Transform class may still be clearer. You can mix both styles in the same pipeline.
One output rule is easy to miss. Only values produced with yield are sent to the next stage. If a generator uses return to produce a final value, that value is not yielded into the pipeline. It is only visible to code directly consuming the generator. In pipeline transforms, use yield for output chunks.
Error Handling in Stream Pipelines
Pipeline error handling is different from single-stream error handling because several independent objects are participating in one operation. The individual failure modes are familiar from earlier chapters. Streams emit error for file-system failures, network drops, invalid data, broken pipes, and other operational problems. The pipeline adds one more question - how should those failures affect the rest of the chain?
The first failure can come from any stage -
| Stage | Typical failures |
|---|---|
| Source | File missing, permission denied, dropped network connection |
| Transform | Parse error, validation failure, unexpected chunk shape |
| Destination | Disk full, broken pipe, remote endpoint closed |
Each error still starts as an error event on the stream that encountered it. With pipe(), you handle those events one by one. With pipeline(), the first failure reaches the callback or promise rejection as the operation result.
That does not undo work already performed by the destination. Suppose a pipeline is reading a 100MB file, transforming it, and writing the result. If the transform errors after 50MB of output has already been written, those 50MB are still in the underlying resource.
For a file destination, the file exists but is incomplete and possibly invalid. pipeline() handles stream-level cleanup. It does not delete partial files, roll back transactions, or restore application-level invariants. One common file pattern is to write to a temporary path and rename it only after success -
import { rename, unlink } from "node:fs/promises";
const tempFile = "output.tmp";
const finalFile = "output.dat";
try {
await pipeline(source, transform, createWriteStream(tempFile));
await rename(tempFile, finalFile);
} catch (err) {
await unlink(tempFile).catch(() => {});
throw err;
}If the pipeline succeeds, the temporary file is renamed to the final name. If it fails, cleanup removes the partial temporary file without hiding the original pipeline error. Keep the temporary path in the same directory and filesystem as the final path when you need the rename to be atomic. If a previous final file already existed, it remains untouched until the successful rename.
For a transactional destination, the same idea moves into the destination's consistency model. Write inside a transaction and commit only after the pipeline completes -
const tx = await db.beginTransaction();
try {
await pipeline(
source,
transform,
new DatabaseWriter(tx)
);
await tx.commit();
} catch (err) {
await tx.rollback();
throw err;
}The difference is worth spelling out. pipeline() calls destroy() on streams that need to be torn down. Application cleanup, such as deleting partial files or rolling back a transaction, belongs to your application.
Once a stream in the chain errors, pipeline() calls destroy(err) on the other streams that have not already completed or closed. Depending on the stream implementation and options, those streams usually emit close. Pending work is abandoned rather than gracefully flushed. That is the right default for a failed chain. If one stage can no longer produce valid output, the rest of the pipeline should stop.
Sometimes you still need to know where the error came from. For example, a source failure might be logged as a read problem, while a destination failure might be logged as a write problem. pipeline() gives you one error - the first failure that reached the operation result. If source-specific handling is needed, encode that information in the error itself -
class SourceStream extends Readable {
_read() {
const err = new Error("Read failed");
err.code = "ERR_SOURCE_READ";
this.destroy(err);
}
}
pipeline(source, transform, destination, (err) => {
if (err && err.code === "ERR_SOURCE_READ") {
console.error("Source read error:", err);
} else if (err) {
console.error("Other error:", err);
}
});Adding a code property lets the operation keep one error path while still preserving source context.
When you need to watch a particular stream inside a larger operation, use stream.finished() for that stream -
import { finished, pipeline } from "node:stream";
const transform = createSomeTransform();
finished(transform, (err) => {
if (err) {
console.error("Transform specifically failed:", err);
}
});
pipeline(source, transform, destination, (err) => {
if (err) {
console.error("Overall pipeline failed:", err);
}
});The finished() utility attaches listeners to one stream and invokes the callback when that stream is no longer readable or writable, errors, or closes prematurely. The pipeline still owns the full operation. finished() lets you observe one stage more closely.
stream.finished()
That narrower role deserves a closer look.
finished() takes a stream and a callback, then invokes the callback when the stream reaches a terminal state -
import { finished } from "node:stream";
finished(someStream, (err) => {
if (err) {
console.error("Stream errored:", err);
} else {
console.log("Stream finished successfully");
}
});The meaning of "finished" depends on the stream type. For a Readable, success means the stream reached EOF and ended normally. If it is destroyed before normal completion, finished() treats that as an error path such as ERR_STREAM_PREMATURE_CLOSE. For a Writable, success means it finished writing and emitted finish. For a Duplex or Transform, both sides have to complete.
That is safer than listening for end or finish directly. Those events cover only part of the lifecycle, while finished() also accounts for error and premature close.
The promise-based version has the same meaning -
import { finished } from "node:stream/promises";
try {
await finished(someStream);
console.log("Stream finished");
} catch (err) {
console.error("Stream errored:", err);
}The promise resolves when the stream completes successfully and rejects if the stream reaches an error path.
One listener detail is easy to overlook in long-lived streams. stream.finished() intentionally leaves event listeners such as error, end, finish, and close attached after the callback is invoked or the promise settles. This lets it catch unexpected late errors from incorrect stream implementations.
For short-lived streams, the stream object is usually collected soon after. For memory-sensitive code or long-lived streams, use cleanup. The callback form returns a cleanup function. The promise form accepts { cleanup: true } -
import { finished } from "node:stream/promises";
await finished(someStream, { cleanup: true }); // Removes listeners after completionThis is useful when a larger stream graph has several destinations. In a tee or broadcast pattern, each destination has its own terminal state -
const dest1 = createWriteStream("output1.txt");
const dest2 = createWriteStream("output2.txt");
source.pipe(dest1);
source.pipe(dest2);
await Promise.all([
finished(dest1),
finished(dest2),
]);
console.log("Both destinations finished");This waits for both destinations to finish writing before the application proceeds.
Error Recovery in Pipelines
Retry belongs outside the stream graph. Once a pipeline fails, some or all of its streams may already be destroyed or closed, so recovery starts by building a new graph. Some errors are temporary and worth retrying. Others point to a permanent condition and should fail the operation.
For example, a dropped network connection may succeed on another attempt. A file read that fails with EACCES usually will not because the file permissions are still wrong. Before adding retry logic, categorize the failure - operational or programmer error, temporary or permanent.
For temporary operational errors, place retry around the whole pipeline -
async function pipelineWithRetry({
maxRetries,
createSource,
createTransforms,
createDestination,
}) {
for (let attempt = 0; attempt <= maxRetries; attempt++) {
try {
await pipeline(
createSource(),
...createTransforms(),
createDestination()
);
return; // Success
} catch (err) {
if (isTransientError(err) && attempt < maxRetries) {
console.log(`Attempt ${attempt + 1} failed, retrying...`);
await delay(1000 * Math.pow(2, attempt)); // Exponential backoff
} else {
throw err; // Give up
}
}
}
}
function isTransientError(err) {
return err.code === "ECONNRESET" || err.code === "ETIMEDOUT"; // Network errors
}This function attempts the pipeline up to maxRetries times. A temporary failure waits with exponential backoff and tries again. A permanent failure, or an exhausted retry budget, reaches the caller.
Every stage is created by a factory because a failed stream instance cannot be reused. Each attempt needs fresh source, transform, and destination objects. For file outputs, pair retry with the temporary-file pattern from the next section so a failed attempt does not leave partial output at the final path.
Fallback uses the same handoff. If one data source fails, run a new pipeline against an alternative source -
async function runWith(sourceFactory, destinationFactory) {
await pipeline(
sourceFactory(),
createTransform(),
destinationFactory()
);
}
try {
await runWith(createPrimarySource, createPrimaryDestination);
} catch (err) {
console.warn("Primary source failed, trying fallback");
await runWith(createFallbackSource, createFallbackDestination);
}That pattern fits redundant data sources, such as trying a CDN first and falling back to an origin server if the CDN is unavailable.
The destination can be swapped the same way -
async function runTo(destinationFactory) {
await pipeline(
createSource(),
createTransform(),
destinationFactory()
);
}
try {
await runTo(createPrimaryDestination);
} catch (err) {
console.warn("Primary destination failed, trying backup");
await runTo(createBackupDestination);
}Again, every attempt creates a fresh stream graph. After the first pipeline fails, any stream instance in that pipeline may be destroyed or closed.
The rule is simple. Decide which errors are recoverable, then implement retry or fallback at the pipeline level. Streams receive chunks and emit events. The application owns retry policy.
Partial Data Concerns
Partial data is the other half of recovery. When a pipeline fails midway through, any data already written to the destination remains there. The pipeline does not automatically clean it up.
That affects data integrity. If a database export fails at 60%, the output file may be 60% complete. A later retry might append duplicate data, overwrite the partial file, or leave the partial file beside the new output, depending on how the destination is opened.
One common file strategy is to write to a temporary location and then use an atomic rename -
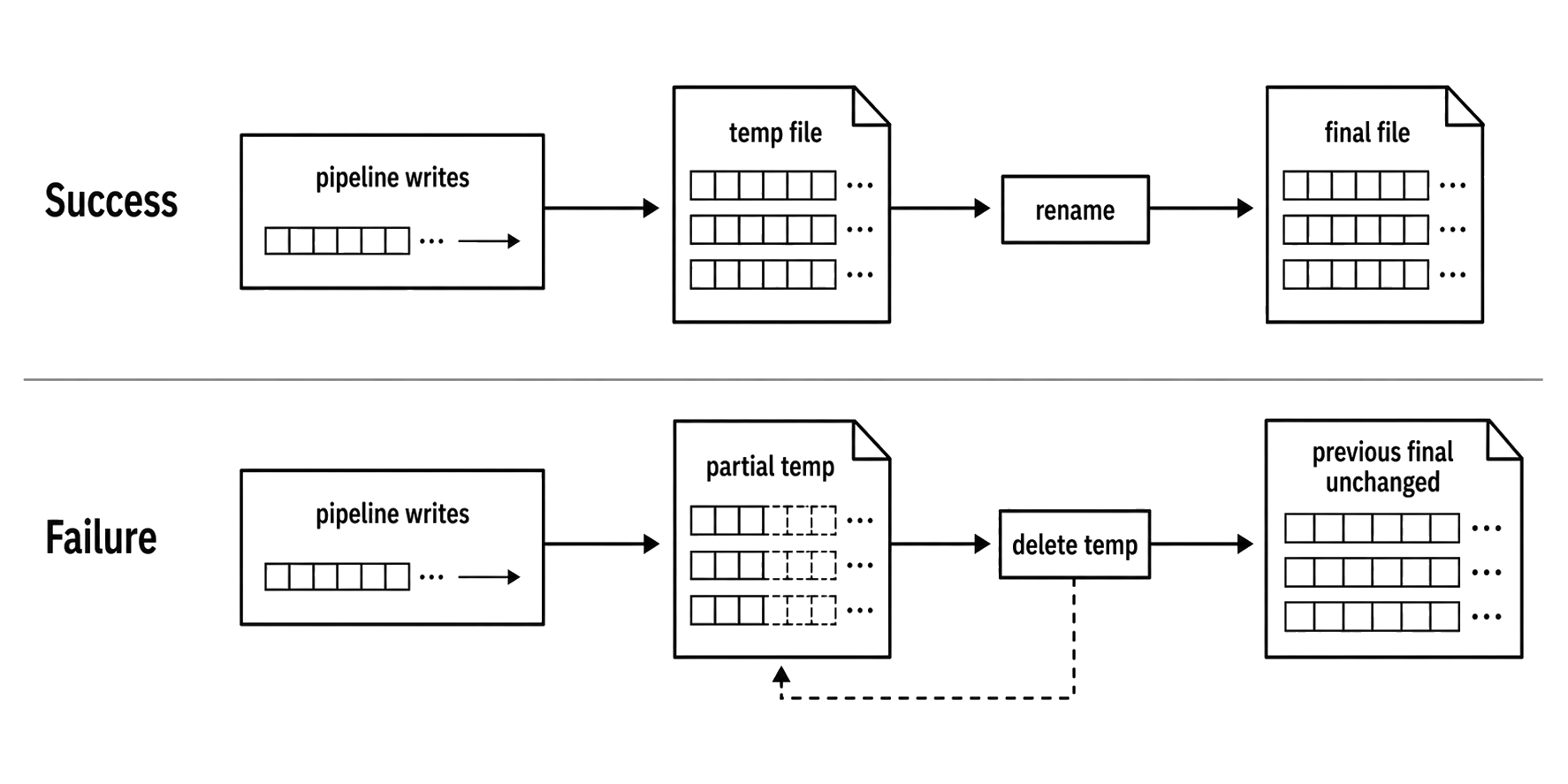
Figure 3.2 - pipeline() cleans up stream objects, not application state. For file outputs, write to a temporary path, promote it only after success, and delete the failed temporary output without touching the previous final file.
const temp = "output.tmp";
const final = "output.dat";
try {
await pipeline(source, transform, createWriteStream(temp));
await rename(temp, final);
} catch (err) {
await unlink(temp).catch(() => {}); // Clean up, ignore errors
throw err;
}This is the usual pattern for file outputs. Keep temp and final in the same directory and filesystem when you need the rename to be atomic. If final already exists, it remains untouched until the successful rename. If it does not exist, it appears only after the pipeline completes.
Append mode only works when duplicate writes are acceptable or can be detected downstream. For log-style outputs with idempotent processing, retrying from the beginning and appending may be a valid policy -
await pipeline(source, transform, createWriteStream("output.log", { flags: "a" }));If the pipeline fails and you retry, the second attempt appends more data. That is only safe when downstream processing can tolerate or remove duplicates.
Transactional destinations offer a stronger guarantee. Databases, message queues, and some cloud storage systems can keep writes invisible until the operation commits -
const tx = await db.beginTransaction();
try {
await pipeline(source, transform, new DatabaseWriter(tx));
await tx.commit();
} catch (err) {
await tx.rollback();
throw err;
}The destination does not commit or make the data visible until the pipeline succeeds, assuming the destination's transaction semantics provide that isolation.
When the destination cannot provide a transaction, a completion marker can separate "file exists" from "file is complete" -
await pipeline(source, transform, createWriteStream("output.dat"));
await writeFile("output.dat.complete", "");Before processing the output file, check for the marker. If the marker does not exist, the file is incomplete and should be discarded or retried.
The right pattern depends on the destination's capabilities and the consistency requirement. Decide what partial failure means before the pipeline starts.
Destroying Streams
The Readable and Writable chapters introduced stream.destroy(). Calling destroy() moves the stream to a destroyed state. With the default emitClose behavior, most core streams then emit close. If you pass an error, the stream reports that error through its normal error path.
Inside a pipeline, destroying one stream usually stops the whole chain. If you destroy a stream with an error, pipeline() uses that error as the pipeline failure and destroys the other unfinished streams -
import { createReadStream, createWriteStream } from "node:fs";
import { pipeline } from "node:stream/promises";
const source = createReadStream("input.txt");
const dest = createWriteStream("output.txt");
const work = pipeline(source, dest);
setTimeout(() => {
source.destroy(new Error("Cancelled by user"));
}, 100);
try {
await work;
} catch (err) {
console.error("Pipeline stopped:", err.message);
}When source.destroy(err) runs, the source stops reading and reports the error you passed. With the default close behavior, it also emits close. pipeline() sees the error, destroys the other unfinished streams in the chain, and rejects the promise with that error.
For user-facing cancellation, prefer AbortSignal. It gives the pipeline a standard cancellation path instead of manually choosing which stream to destroy -
const controller = new AbortController();
const work = pipeline(source, dest, { signal: controller.signal });
setTimeout(() => {
controller.abort();
}, 100);
try {
await work;
} catch (err) {
if (err.code === "ABORT_ERR") {
console.log("Pipeline cancelled");
} else {
throw err;
}
}You can also destroy a stream with no error -
source.destroy();In that case, the stream is destroyed but no error event is emitted by that stream. If this happens before the pipeline has naturally completed, pipeline() still treats the early close as a failure and reports ERR_STREAM_PREMATURE_CLOSE. It is not a successful cancellation signal.
destroy() is idempotent. Calling it multiple times on the same stream does nothing after the first call. The stream is destroyed once, and later destroy calls are ignored.
Destroying a stream can discard buffered data. If a Writable has buffered writes that have not been flushed yet, they may be lost. If a Readable has buffered data that has not been consumed yet, it is no longer delivered. Destroy means "stop and tear down pending state", not "gracefully finish pending operations".
If you need graceful shutdown, meaning the writable should finish writing buffered data before closing, use end() instead of destroy() -
writable.end(); // Finish writing buffered data, then closeBut end() is a writable-side operation. For a readable stream, there is no equivalent "finish producing what remains and then close" call. You either consume the data or destroy the stream.
Async Iteration Pipelines
The Readable Streams chapter used for await...of to consume streams with automatic backpressure handling. The same pattern can also form the middle of a pipeline, especially when the transformation is easier to express as ordinary control flow than as a Transform subclass.
As a refresher, the iterator does not pull the next chunk until the current iteration completes. If the loop awaits asynchronous work, the readable stream waits with it -
for await (const chunk of readableStream) {
await processAsync(chunk); // Stream waits for this
}The full backpressure mechanics are covered in the "Backpressure in Async Iteration" section of the Readable Streams chapter. Here, the useful detail is how that pattern changes pipeline construction.
You can read from a source with for await...of, transform each chunk, and write to a destination yourself -
import { once } from "node:events";
import { createReadStream, createWriteStream } from "node:fs";
import { finished } from "node:stream/promises";
const source = createReadStream("input.txt", { encoding: "utf8" });
const dest = createWriteStream("output.txt");
try {
for await (const chunk of source) {
const transformed = chunk.toUpperCase();
const ok = dest.write(transformed);
if (!ok) {
await once(dest, "drain");
}
}
dest.end();
await finished(dest);
} catch (err) {
dest.destroy();
throw err;
}This is a manual pipeline. It pulls from the source, transforms each chunk, and writes to the destination. The write() return value is the backpressure signal. When it returns false, the loop waits for drain before reading more. Forgetting that wait is how manual stream loops turn into unbounded buffering.
A cleaner version keeps the transformation as an async generator and lets pipeline() own the stream lifecycle -
async function* transform(source) {
for await (const chunk of source) {
yield chunk.toUpperCase();
}
}
const source = createReadStream("input.txt", { encoding: "utf8" });
const transformed = Readable.from(transform(source));
const dest = createWriteStream("output.txt");
await pipeline(transformed, dest);Readable.from() creates the stream wrapper around the generator. pipeline() then handles completion and error coordination for the stream pair.
You can chain multiple generator transforms -
async function* toUppercase(source) {
for await (const chunk of source) {
yield chunk.toUpperCase();
}
}
async function* filterEmpty(source) {
for await (const line of source) {
if (line.trim().length > 0) {
yield line;
}
}
}
await pipeline(
source,
toUppercase,
filterEmpty,
dest
);Each generator becomes a pipeline stage. The stage body remains a plain for await loop, while pipeline() handles composition.
This style is especially useful for objectMode pipelines, where each chunk is a structured object -
async function* parseJSONLines(source) {
let buffer = "";
for await (const chunk of source) {
buffer += chunk;
const lines = buffer.split("\n");
buffer = lines.pop();
for (const line of lines) {
if (line.trim()) {
yield JSON.parse(line);
}
}
}
if (buffer.trim()) {
yield JSON.parse(buffer);
}
}
async function* pickName(source) {
for await (const obj of source) {
yield { name: obj.name };
}
}
async function* serializeJSON(source) {
for await (const obj of source) {
yield JSON.stringify(obj) + "\n";
}
}
await pipeline(
createReadStream("users.ndjson", { encoding: "utf8" }),
parseJSONLines,
pickName,
serializeJSON,
createWriteStream("names.ndjson")
);The middle of this pipeline is object-mode. parseJSONLines yields JavaScript objects, and pickName receives JavaScript objects. Before writing to a byte-mode file stream, serializeJSON converts objects back to strings.
Each stage is a function from source to async iterable. For transformations that fit naturally as for await loops, generator stages often make the data path easier to review than a stack of custom Transform subclasses.
For newline-delimited JSON, keep parsing at line breaks. Parsing arbitrary byte chunks is wrong because a single JSON record can be split across chunks, and several records can arrive in one chunk.
Backpressure with Async Iteration in Pipelines
The same backpressure rule carries through every async-iteration pipeline. The loop must await the work that determines when the next chunk is safe to read.
That gives you three practical rules -
| Rule | Why it helps |
|---|---|
| Await async work | Processing speed becomes the backpressure signal. |
| Avoid unbounded promise arrays | promises.push(processAsync(chunk)) can read the whole stream into memory. |
| Bound concurrency deliberately | Parallel work needs an explicit limit, such as one enforced with p-limit. |
Without await, the loop continues immediately and the stream can keep producing chunks -
// WRONG - loses backpressure
for await (const chunk of source) {
slowOperation(chunk); // No await! Loop continues immediately
}
// CORRECT - maintains backpressure
for await (const chunk of source) {
await slowOperation(chunk); // Stream waits until this completes
}The advantage of manual async iteration is direct control over data flow. The cost is that you own the error handling and cleanup that pipeline() would otherwise coordinate.
For the full mechanics of how the async iterator protocol implements backpressure, see the "Backpressure in Async Iteration - How It Works" section in the Readable Streams chapter.
Composable Transforms
The Transform Streams chapter covered custom transform classes. In larger pipeline code, reusable components usually start as factory functions.
The pattern is simple. Create a function that returns a fresh, configured stream instance -
import { Transform } from "node:stream";
import { StringDecoder } from "node:string_decoder";
function createSimpleCSVParser() {
const decoder = new StringDecoder("utf8");
let buffer = "";
let headers = null;
function parseLine(line) {
return line.replace(/\r$/, "").split(",");
}
function emitLine(stream, line) {
if (!line.trim()) return;
if (!headers) {
headers = parseLine(line);
return;
}
const values = parseLine(line);
const row = {};
for (let i = 0; i < headers.length; i++) {
row[headers[i]] = values[i];
}
stream.push(row);
}
return new Transform({
readableObjectMode: true,
transform(chunk, encoding, callback) {
buffer += typeof chunk === "string" ? chunk : decoder.write(chunk);
const lines = buffer.split("\n");
buffer = lines.pop();
for (const line of lines) {
emitLine(this, line);
}
callback();
},
flush(callback) {
buffer += decoder.end();
emitLine(this, buffer);
callback();
},
});
}
// Use in multiple pipelines
await pipeline(source1, createSimpleCSVParser(), dest1);
await pipeline(source2, createSimpleCSVParser(), dest2);Each call to createSimpleCSVParser() returns a fresh Transform instance. A stream instance cannot be reused across pipelines after it ends or errors, but the factory function can be reused freely. This parser is intentionally simplified. Real CSV needs a parser that handles quoted fields, escaped quotes, and embedded newlines.
You can make factories configurable -
function createFieldExtractor(fields) {
return new Transform({
objectMode: true,
transform(obj, encoding, callback) {
const extracted = {};
for (const field of fields) {
extracted[field] = obj[field];
}
this.push(extracted);
callback();
},
});
}
await pipeline(
source,
createFieldExtractor(["name", "email"]),
dest
);Now the transform is parameterized. Different pipelines can extract different fields. These examples assume the destination accepts objects. If the final destination is a file stream or socket, add a serializer before it.
The same factory style can wrap a whole sequence -
function createProcessingPipeline(source, dest) {
return pipeline(
source,
createSimpleCSVParser(),
createFieldExtractor(["name", "email"]),
createValidator(),
dest
);
}
await createProcessingPipeline(source1, dest1);
await createProcessingPipeline(source2, dest2);The createProcessingPipeline() function contains the transformation sequence. The caller supplies a source and destination, and the function wires the intermediate stages together.
You can also compose generator functions -
import { StringDecoder } from "node:string_decoder";
const parseCSV = async function* (source) {
const decoder = new StringDecoder("utf8");
let buffer = "";
let headers = null;
function parseLine(line) {
return line.replace(/\r$/, "").split(",");
}
function rowFromLine(line) {
if (!line.trim()) return null;
if (!headers) {
headers = parseLine(line);
return null;
}
const values = parseLine(line);
const row = {};
for (let i = 0; i < headers.length; i++) {
row[headers[i]] = values[i];
}
return row;
}
for await (const chunk of source) {
buffer += typeof chunk === "string" ? chunk : decoder.write(chunk);
const lines = buffer.split("\n");
buffer = lines.pop();
for (const line of lines) {
const row = rowFromLine(line);
if (row) yield row;
}
}
buffer += decoder.end();
const finalRow = rowFromLine(buffer);
if (finalRow) yield finalRow;
};
const extractFields = (fields) =>
async function* (source) {
for await (const obj of source) {
const extracted = {};
for (const field of fields) {
extracted[field] = obj[field];
}
yield extracted;
}
};
await pipeline(
source,
parseCSV,
extractFields(["name", "email"]),
dest
);Each generator is a function from async iterable to async iterable. pipeline() connects each returned iterable to the next stage, giving generator composition the same lifecycle wrapper as stream-instance composition.
Pipeline Segments
A pipeline segment is a reusable piece of a pipeline. It might be a single transform, a chain of transforms, or a generator that applies validation and routing rules. The segment is reusable only if its lifecycle is clear.
Side outputs are the common place to lose that clarity. A transform that calls sideDest.write(obj) and immediately invokes its callback ignores side-channel backpressure and side-channel errors. If a stage writes to another destination, that destination is part of the stage lifecycle and must be handled as deliberately as the main output -
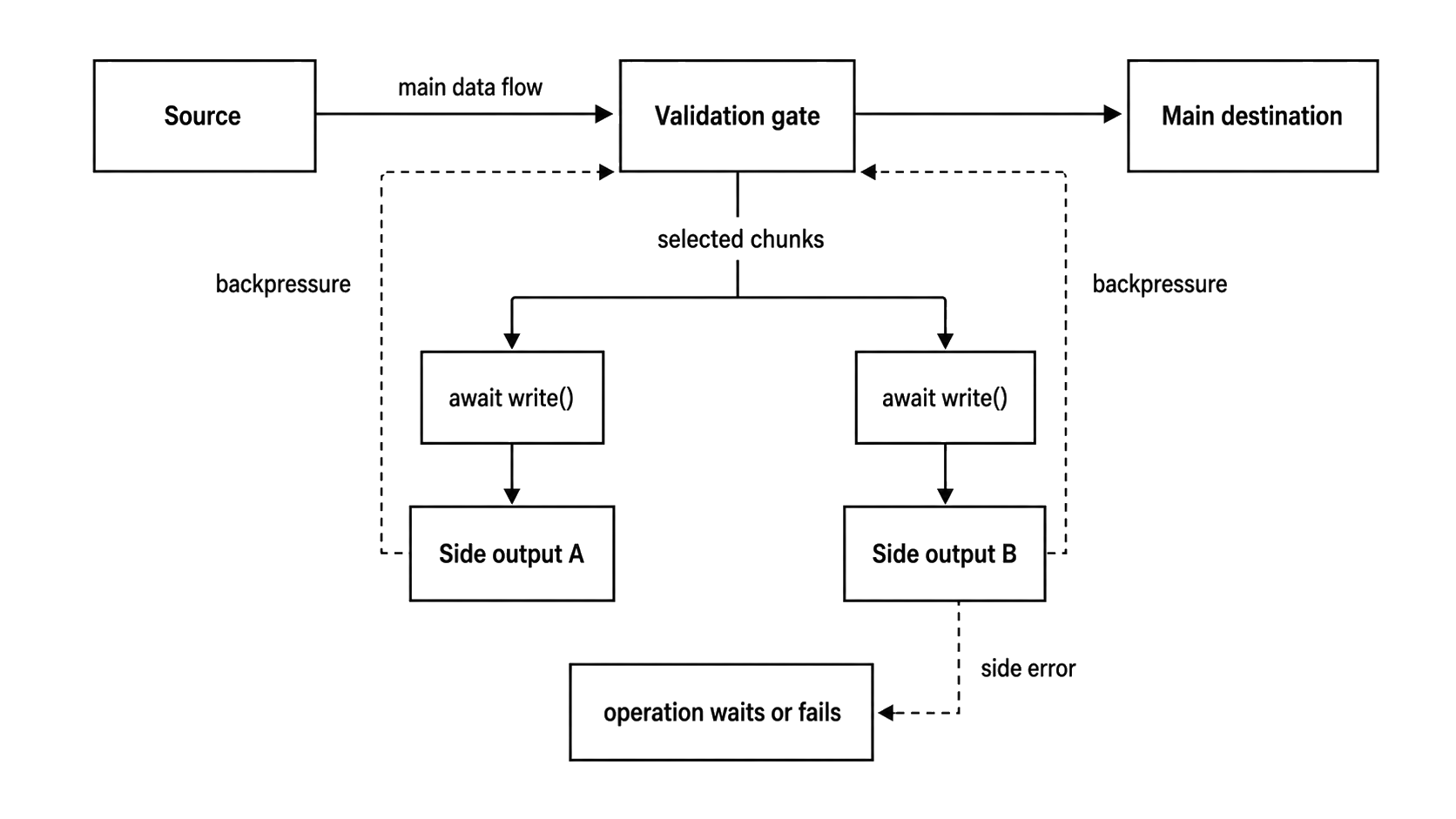
Figure 3.3 - Side outputs are still part of the operation. Await their writes, observe their errors, and close them deliberately so a secondary destination cannot silently outrun or outfail the main pipeline.
import { finished } from "node:stream/promises";
function createSideWriter(dest) {
let sideError;
function rememberError(err) {
sideError = err;
}
dest.on("error", rememberError);
return {
write(chunk) {
if (sideError) return Promise.reject(sideError);
return new Promise((resolve, reject) => {
dest.write(chunk, (err) => {
if (err) {
sideError = err;
reject(err);
} else if (sideError) {
reject(sideError);
} else {
resolve();
}
});
});
},
close() {
dest.off("error", rememberError);
},
};
}
async function* validateRows(source, schema, invalidDest, { signal }) {
const invalidWriter = createSideWriter(invalidDest);
try {
for await (const obj of source) {
signal.throwIfAborted();
if (schema.validate(obj)) {
yield obj;
} else {
await invalidWriter.write(obj);
}
}
} finally {
if (!invalidDest.destroyed && !invalidDest.writableEnded) {
invalidDest.end();
}
try {
await finished(invalidDest, { cleanup: true });
} finally {
invalidWriter.close();
}
}
}You use it like this -
import { Writable } from "node:stream";
const invalidRows = new Writable({
objectMode: true,
write(row, encoding, callback) {
errorStore.save(row).then(
() => callback(),
(err) => callback(err)
);
},
});
await pipeline(
source,
(source, options) => validateRows(source, mySchema, invalidRows, options),
dest
);Valid objects continue to dest. Invalid objects go to invalidRows. The side writes are awaited, finalization is explicit, and errors from the side destination can still fail the pipeline instead of being lost.
For conditional processing, prefer transforming the current item and yielding the result instead of writing into separate transform streams from inside _transform() -
async function* routeByCondition(
source,
condition,
whenTrue,
whenFalse,
{ signal }
) {
for await (const obj of source) {
signal.throwIfAborted();
const passed = await condition(obj);
const handler = passed ? whenTrue : whenFalse;
yield await handler(obj);
}
}Validation, side outputs, and conditional transforms are useful building blocks. They become risky only when they interact with destinations outside the main pipeline without carrying over backpressure, error handling, and finalization.
Tee and Broadcast Patterns
Sometimes the same data has to reach multiple destinations. That shape is usually called a tee or broadcast pattern.
The simplest way to tee a stream is to pipe it to multiple destinations and let the slowest destination limit throughput -
import { finished } from "node:stream/promises";
source.pipe(dest1);
source.pipe(dest2);
try {
await Promise.all([
finished(source, { cleanup: true }),
finished(dest1, { cleanup: true }),
finished(dest2, { cleanup: true }),
]);
} catch (err) {
source.destroy(err);
dest1.destroy(err);
dest2.destroy(err);
throw err;
}Both dest1 and dest2 receive the same data from source. The source emits each chunk once, and both pipes forward it to their destinations. Waiting on finished() for all three streams gives the application one place to observe completion or failure, and the catch block tears down the whole group if one stream fails.
The backpressure trade-off comes from sharing one source. If dest1 is slow and signals backpressure, the source pauses. dest2 might be ready for more data, but it waits too. The source cannot pause for one pipe destination while continuing freely for another, so the slowest destination controls the pace for all destinations.
If this is acceptable, simple piping is the right tool. Avoid manually handling source.on("data") and calling dest.write() for each destination unless you also implement backpressure, error propagation, and finalization for every destination. That pattern is easy to get wrong and can buffer without bound.
Truly independent destinations with bounded memory require a deliberate fan-out design - queues with explicit limits, per-destination failure policy, and a clear answer to whether a slow or failed destination should slow, drop, retry, or abort the whole operation. That is application policy. pipeline() cannot infer it from the stream objects alone.
AbortSignal Integration
Streams support AbortSignal for cancellation. You can pass a signal to the promise-based pipeline(), and if the signal is aborted, the pipeline is destroyed -
import { pipeline } from "node:stream/promises";
const controller = new AbortController();
try {
await pipeline(source, transform, dest, { signal: controller.signal });
} catch (err) {
if (err.code === "ABORT_ERR") {
console.log("Pipeline cancelled");
} else {
throw err;
}
}
// To cancel: controller.abort();When controller.abort() runs, pipeline() requests destruction of the stream chain and the promise rejects with an AbortError whose code is ABORT_ERR. Core streams tear down promptly. Custom streams should observe the signal or implement _destroy() cleanup so their own pending operations do not keep running after the pipeline has failed.
This is the usual shape for user-initiated cancellation, timeouts, and cleanup in long-running operations.
You can also create a timeout signal -
const signal = AbortSignal.timeout(5000); // 5 second timeout
try {
await pipeline(source, transform, dest, { signal });
console.log("Pipeline completed");
} catch (err) {
if (err.code === "ABORT_ERR") {
console.log("Pipeline timed out");
} else {
throw err;
}
}If the pipeline does not complete within five seconds, the timeout signal aborts it.
For complex scenarios with multiple cancellation sources, you can use AbortSignal.any() -
const userCancel = new AbortController();
const timeout = AbortSignal.timeout(10000);
const signal = AbortSignal.any([userCancel.signal, timeout]);
try {
await pipeline(source, transform, dest, { signal });
} catch (err) {
if (err.code === "ABORT_ERR") {
console.log("Cancelled by either user or timeout");
} else {
throw err;
}
}This creates a composite signal that aborts if either the user cancels or the timeout expires.
AbortSignal.any() is available in current Node.js releases. It was added in Node.js v18.17 and v20.3. AbortSignal integration makes cancellation explicit and standardized. Instead of manually calling destroy() on a chosen stream, you abort a signal and let the pipeline handle cleanup across the chain.
Pipelines define who owns failure, when unfinished streams are destroyed, how partial outputs are handled, and how cancellation reaches every stage. That lifecycle wrapper is what makes stream code maintainable once it leaves toy examples.
Related Chapters
- Earlier - Node.js Transform Streams
- Next - Node.js File Descriptors