Node.js Transform Streams: _transform(), _flush(), and Backpressure
A Transform stream is a Duplex stream with one added contract - anything written to the writable side is handled by _transform(), and whatever _transform() produces is emitted from the readable side.
That is the real difference between a Transform and a raw Duplex. A raw Duplex has two directions on one object, but those directions can be completely independent. A Transform also has a writable side and a readable side, but the writable side feeds the readable side. Compression, encryption, line splitting, protocol framing, filtering, aggregation, and object serialization all follow this pattern.
The amount of output is not fixed. One input chunk can produce nothing, one output chunk, or several output chunks. Some transforms emit output immediately. Others keep partial state and wait until more input arrives, or until _flush() runs at the end.
Backpressure moves through the same handoff. The writable side can tell upstream producers to slow down, and the readable side can delay later _transform() calls when downstream consumers are not reading fast enough.
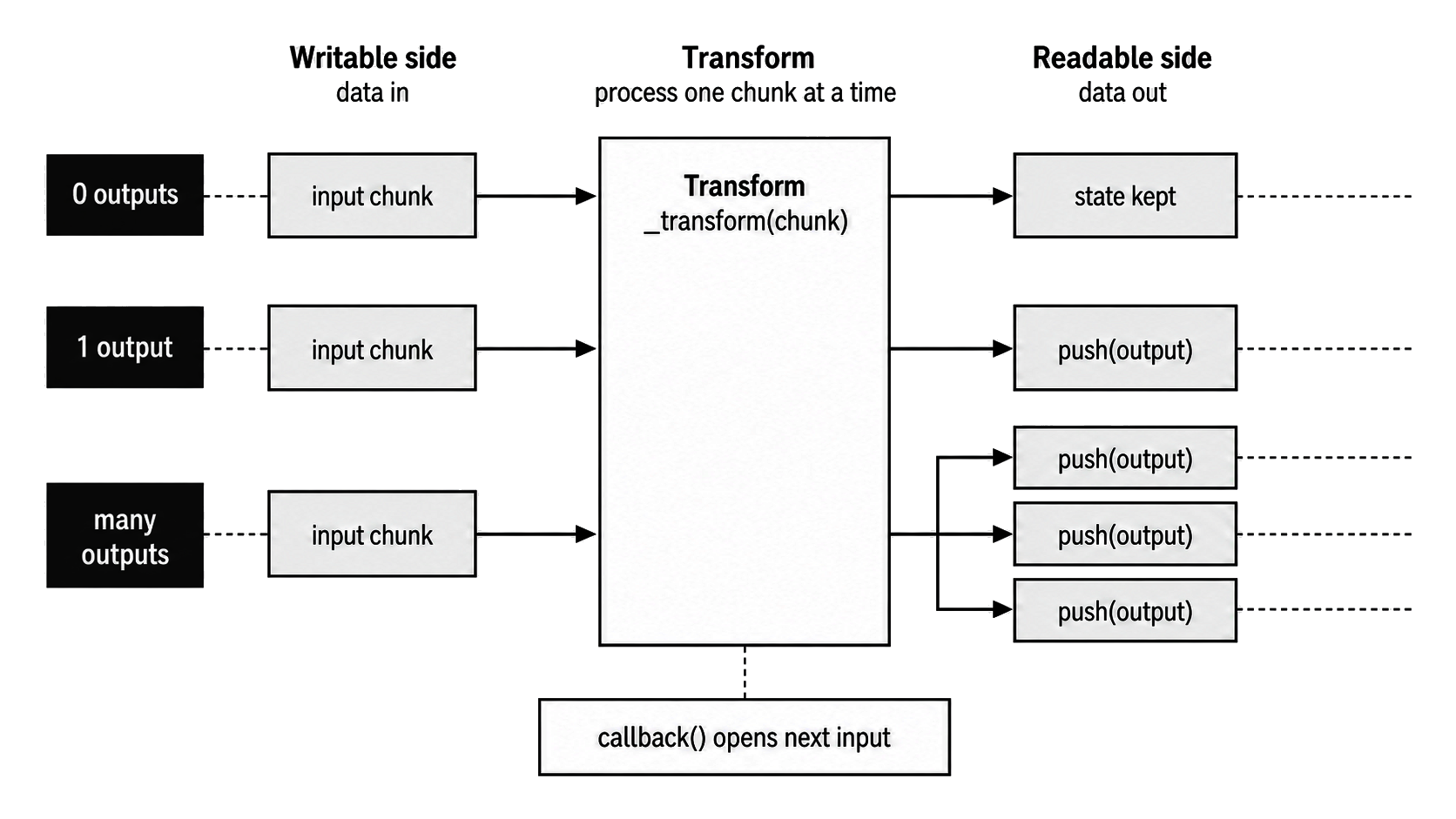
Figure 1 - A Transform connects writable input to readable output through one processing contract. A single input chunk may produce no output, one chunk, or several chunks.
Duplex Streams
Duplex is the base class to understand first because Transform inherits its two-sided stream model.
A Duplex stream is readable and writable at the same time. You can call write() on it, read from it, attach data listeners, and listen for writable lifecycle events such as finish. All of that happens through one object, but the readable and writable sides still keep separate state. Writing affects the writable side. Reading pulls from the readable side.
That separation fits bidirectional I/O. A TCP socket is the usual example. Bytes you write go to the remote endpoint, while bytes you read come back from that endpoint. The readable data may be a response to something you wrote, but the socket object is not transforming your last write() call into the next readable chunk.
At the class level, Duplex extends Readable and implements the Writable side as well. A custom Duplex usually provides both _read() and _write() -
import { Duplex } from "node:stream";
class MinimalDuplex extends Duplex {
_read() {
this.push("readable data");
this.push(null);
}
_write(chunk, encoding, callback) {
console.log("Received -", chunk.toString());
callback();
}
}_read() runs when the readable side needs data. _write() runs when something writes to the writable side. These methods can share state if you design them that way, but Node does not treat one as the implementation of the other.
Here is the stream in use -
const duplex = new MinimalDuplex();
duplex.on("data", (chunk) => {
console.log("Read -", chunk.toString());
});
duplex.write("written data");
duplex.end();This produces output from both sides. The written chunk is handled by _write(), while the readable chunk comes from _read(). This class never says that readable data should be produced from the writable input.
Half-Open Duplex State
The same independence shows up when a duplex stream ends. The allowHalfOpen option controls one part of that behavior. By default, it is true, which means the readable side and writable side can end independently. A TCP connection can be half-closed this way. One endpoint may finish sending while it can still receive.
With allowHalfOpen: false, Node automatically ends the writable side when the readable side ends. Pay close attention to that direction. In Node v24, calling duplex.end() ends the writable side. It does not automatically push readable EOF for a custom Duplex.
const duplex = new Duplex({
allowHalfOpen: false,
read() {
this.push(null);
},
write(chunk, encoding, callback) {
callback();
},
});Here _read() ends the readable side by pushing null. Because allowHalfOpen is false, Node also ends the writable side. This option is useful when the underlying resource should not stay writable after readable EOF. It is not a shortcut for making end() finish the readable side.
Subprocess stdio is a good reminder to follow the public stream contract. A child process exposes separate streams. stdin is a Writable, while stdout and stderr are Readable. Some runtime objects may inherit from lower-level duplex handles, but application code should use the documented stream direction as the API contract.
A Small Buffered Duplex
Application code rarely needs to implement raw Duplex streams. When it does, bugs often come from one wrong assumption - _read() may run before _write() has any data ready.
The small queue below works in both orders - write-before-read and read-before-write.
class BufferedDuplex extends Duplex {
constructor(options) {
super(options);
this.buffer = [];
this.waitingForRead = false;
}
_write(chunk, encoding, callback) {
this.buffer.push(chunk);
if (this.waitingForRead) this._drainBuffer();
callback();
}
_read() {
this.waitingForRead = true;
this._drainBuffer();
}
_final(callback) {
this.push(null);
callback();
}
_drainBuffer() {
while (this.buffer.length > 0) {
this.waitingForRead = false;
if (!this.push(this.buffer.shift())) return;
}
this.waitingForRead = true;
}
}The detail to watch is inside _write(). If data arrives after a reader was already waiting, the stream drains the buffer immediately. A queue that only pushes from _read() can stall, because Node may not call _read() again just because _write() stored a chunk.
This is only a demonstration, not a production queue. It has no size bound, cancellation policy, or multi-consumer behavior. What it shows is state ownership. _write() owns incoming chunks, _read() owns readable demand, and the shared buffer connects those two sides.
Error handling follows the same whole-stream behavior. With the default autoDestroy: true, passing an error to a _write() callback emits error, destroys the stream, and usually emits close. If you deliberately configure older manual lifetime behavior, you own more of the cleanup. For current Node code, treat implementation errors as whole-stream failures unless you have a strong reason to keep a custom half-open object alive.
Calling destroy(err) tears down the stream object -
duplex.destroy(new Error("fatal stream failure"));That shuts down both sides. For sockets and subprocess wrappers, this means abandoning the underlying resource, not merely stopping one direction.
Transform Streams
Transform streams are the usual abstraction for in-process data processors. A Transform is still a Duplex, but it is a specialized one. The writable side receives input chunks, _transform() processes them, and the readable side emits the output.
The standard library uses this pattern for streams such as zlib.createGzip() and crypto.createCipheriv(). You write uncompressed bytes to a gzip stream and read compressed bytes from it. You write plaintext to a cipher stream and read ciphertext from it. In both cases, the readable data comes from the writable input.
Custom Transform implementations provide _transform() -
_transform(chunk, encoding, callback)Node calls _transform() once for each input chunk. The method can call this.push() zero or more times, but it must call callback() exactly once when the current chunk has been fully handled. That callback controls progress. _transform() is never called in parallel, because Node queues writes and waits for the callback before delivering the next chunk.
The chunks that arrive in _transform() follow writable-side rules. By default, strings written to the stream are converted to Buffer objects before _transform() receives them. That comes from the decodeStrings: true default inherited from Writable. Set decodeStrings: false only when your transform needs to tell original strings apart from buffers.
const keepStrings = new Transform({
decodeStrings: false,
transform(chunk, encoding, callback) {
console.log(typeof chunk, encoding);
callback(null, chunk);
},
});With the default settings, writing "abc" gives _transform() a Buffer, and the encoding value is "buffer". With decodeStrings: false, the same write gives _transform() the original string and the encoding value from write(), usually "utf8". Most transforms should keep the default because byte-oriented code is easier to reason about after input crosses the stream boundary.
Here is a small uppercase transform -
import { Transform } from "node:stream";
class UppercaseTransform extends Transform {
_transform(chunk, encoding, callback) {
this.push(chunk.toString().toUpperCase());
callback();
}
}Using it directly -
const upper = new UppercaseTransform();
upper.on("data", (chunk) => console.log(chunk.toString()));
upper.write("hello");
upper.write("world");
upper.end();The output chunks are "HELLO" and "WORLD". The base Transform class supplies the readable and writable plumbing. Your subclass supplies the transformation logic.
Errors belong in the callback -
_transform(chunk, encoding, callback) {
try {
const result = JSON.parse(chunk.toString());
callback(null, JSON.stringify(result));
} catch (err) {
callback(err);
}
}Passing callback(null, output) is the same as calling this.push(output) and then callback(). Passing an error stops normal processing and emits error.
How Transform Coordinates the Two Sides
Transform hides _read() and _write() from your subclass, but those methods still exist in the base class. The writable side accepts chunks through write(). The base _write() queues one chunk for _transform(). Your _transform() runs. Output moves to the readable side through push() or through the second callback argument. Once you call the callback, the current input chunk is done and the base class may move to the next queued write.
You can think of that callback as a gate for the transform's internal queue.
If _transform() performs asynchronous work, the writable side cannot hand the next chunk to your implementation until the callback fires. This serial behavior protects instance state. A parser can keep fields like this.buffer, this.expectedLength, or this.batch without guarding them against concurrent _transform() calls.
_transform(chunk, encoding, callback) {
this.pending += chunk.toString();
setImmediate(() => {
this.push(this.pending.toUpperCase());
this.pending = "";
callback();
});
}Even though this method finishes later in the event loop, Node does not run a second _transform() at the same time. Later writes wait behind the callback. If you forget the callback, the stream hangs because the queue is waiting to move forward.
The readable side has its own queue. this.push() appends output to the readable buffer. If no consumer is reading, output stays there. Once the readable buffer reaches its threshold, push() starts returning false. The current _transform() may still finish, but the base class stops asking for more transformed output until the readable side is consumed.
The writable side can also be under pressure. A fast producer may keep calling write() while the readable side is full, so written chunks collect in the transform's writable-side buffer. A transform can have output waiting for downstream and input waiting from upstream at the same time. Treat them as separate queues with separate thresholds.
This model helps when a transform gets stuck. If _transform() is currently running, the next input chunk is waiting for its callback. If readable output is not being consumed, later _transform() calls can pause behind readable-side pressure. If upstream ignores write() returning false, writable-side buffering can grow even while readable-side backpressure is working. If _flush() never calls its callback, the readable side never reaches EOF.
The hard bugs usually come from mixing up which side owns which state.
One-to-Many and Filtering
A transform can emit multiple chunks for one input chunk. The common mistake is assuming that each input chunk is already a complete logical unit.
A line splitter cannot make that assumption because line breaks can appear anywhere relative to stream chunk boundaries -
class LineSplitter extends Transform {
constructor(options) {
super(options);
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
let index;
while ((index = this.buffer.indexOf("\n")) !== -1) {
this.push(this.buffer.slice(0, index + 1));
this.buffer = this.buffer.slice(index + 1);
}
callback();
}
_flush(callback) {
if (this.buffer.length > 0) this.push(this.buffer);
callback();
}
}If the input arrives as "hel" and then "lo\nworld\n", this transform emits "hello\n" and "world\n". A per-chunk split("\n") would treat "hel" and "lo\n" as separate pieces even though they belong to the same logical line.
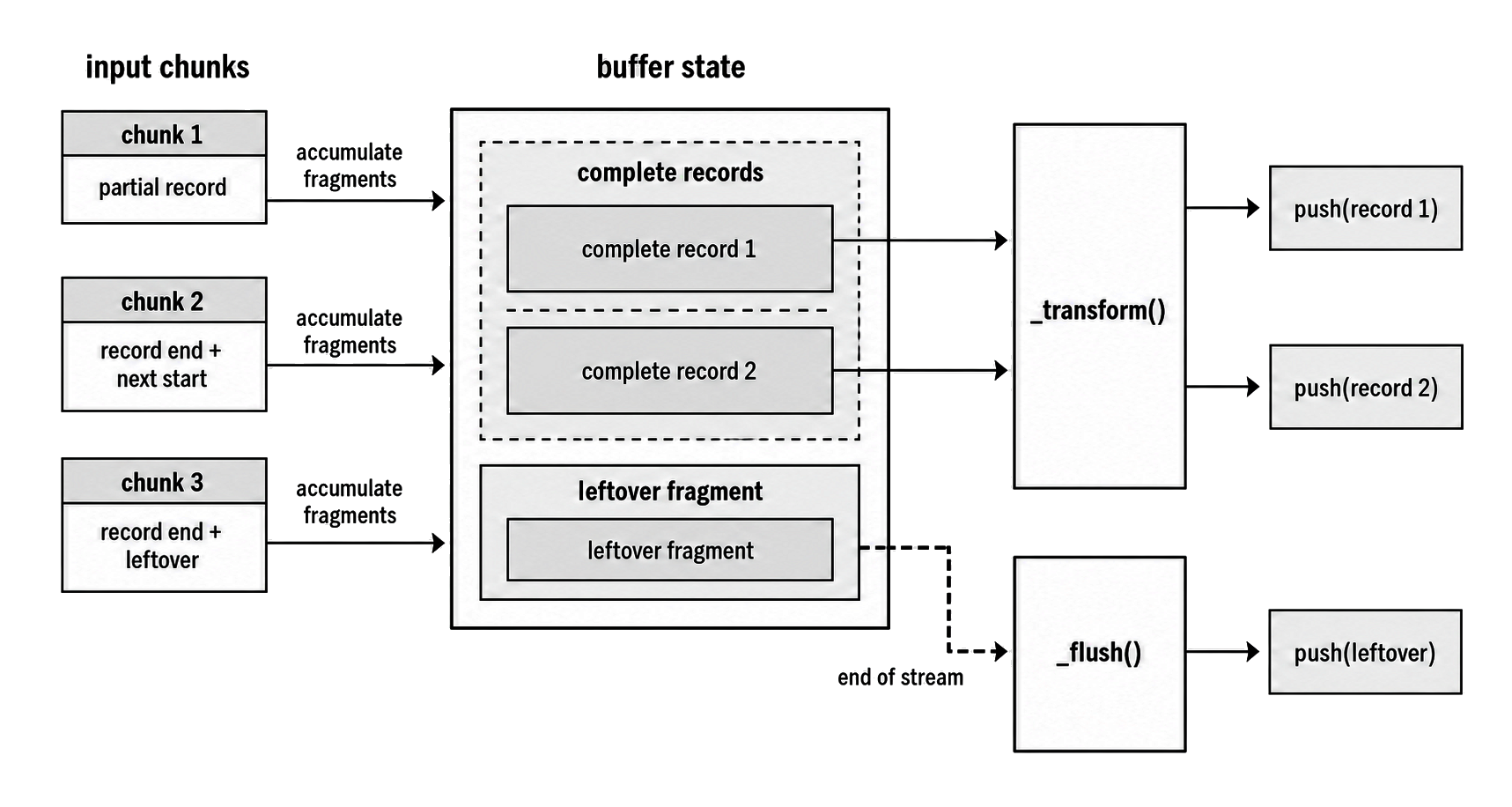
Figure 2 - Chunk breaks are not record breaks. Parser state keeps fragments until complete records can be emitted, and _flush() decides what happens to remaining data at EOF.
Filtering is the zero-output version of the same contract. This transform passes through non-comment chunks -
_transform(chunk, encoding, callback) {
const text = chunk.toString();
if (!text.startsWith("#")) {
this.push(chunk);
}
callback();
}That filter is chunk-based, not line-based. If you want to filter lines, split lines first and filter only after a complete line has been assembled. Chunk filters are valid only when the chunk is already the unit you care about.
A line-safe filter keeps the same handoff state as the splitter -
class NonEmptyLineFilter extends Transform {
constructor(options) {
super(options);
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
let index;
while ((index = this.buffer.indexOf("\n")) !== -1) {
const line = this.buffer.slice(0, index + 1);
this.buffer = this.buffer.slice(index + 1);
if (line.trim() !== "") this.push(line);
}
callback();
}
_flush(callback) {
if (this.buffer.trim() !== "") this.push(this.buffer);
callback();
}
}This version can receive "hel" and "lo\n\nworld" and still filter logical lines rather than raw chunks. The transform assembles lines before it decides whether to emit them.
The _flush() Method
_flush(callback) runs after all written chunks have been processed and before the readable side ends. It exists for state that remains after the last _transform() call.
The delimiter parser below uses the same buffering pattern as the line splitter, but its EOF behavior is easier to see -
class DelimiterParser extends Transform {
constructor(delimiter, options) {
super(options);
this.delimiter = delimiter;
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
const parts = this.buffer.split(this.delimiter);
this.buffer = parts.pop();
for (const part of parts) this.push(part);
callback();
}
_flush(callback) {
if (this.buffer.length > 0) this.push(this.buffer);
callback();
}
}Without _flush(), a final value without a trailing delimiter would remain in this.buffer and disappear when the stream ends. With _flush(), the parser decides that leftover data is a valid final unit.
That decision depends on the protocol. Any decoder, parser, or aggregator that buffers across chunks needs an EOF policy. Some transforms emit the remaining data. Some reject partial input as invalid. Some intentionally drop incomplete trailing state. When remaining state needs to be handled, _flush() is where that logic belongs.
If flushing can fail, pass the error to the callback -
_flush(callback) {
try {
if (this.buffer.length > 0) {
this.push(this.parseFinal(this.buffer));
}
callback();
} catch (err) {
callback(err);
}
}Byte-to-Object Transforms
Object mode can be different on the two sides of a Transform. objectMode: true turns on object mode for both readable and writable sides. readableObjectMode: true means byte or string input can produce JavaScript object output. writableObjectMode: true means object input can produce byte or string output.
An NDJSON parser reads bytes or strings and emits objects, so only the readable side needs object mode -
class NDJSONParser extends Transform {
constructor(options) {
super({ ...options, readableObjectMode: true });
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
const lines = this.buffer.split("\n");
this.buffer = lines.pop();
for (const line of lines) {
if (line.trim() === "") continue;
try {
this.push(JSON.parse(line));
} catch (err) {
return callback(err);
}
}
callback();
}
_flush(callback) {
if (this.buffer.trim() === "") return callback();
try {
this.push(JSON.parse(this.buffer));
callback();
} catch (err) {
callback(err);
}
}
}The writable side stays in byte mode. The parser can receive Buffer chunks from a file or socket, preserve incomplete lines between calls, and push parsed objects downstream.
The reverse direction uses writableObjectMode -
class JSONLineStringifier extends Transform {
constructor(options) {
super({ ...options, writableObjectMode: true });
}
_transform(obj, encoding, callback) {
try {
callback(null, `${JSON.stringify(obj)}\n`);
} catch (err) {
callback(err);
}
}
}Here, objects enter the writable side and strings leave the readable side.
Common Custom Transform Patterns
A map transform changes each input object into another object -
class FieldExtractor extends Transform {
constructor(fields, options) {
super({ ...options, objectMode: true });
this.fields = fields;
}
_transform(obj, encoding, callback) {
const extracted = {};
for (const field of this.fields) {
if (obj[field] !== undefined) extracted[field] = obj[field];
}
callback(null, extracted);
}
}Both sides use object mode because objects enter and objects leave.
A split transform has a different shape. It may need to accumulate bytes until it can emit a fixed-size piece -
class ChunkSplitter extends Transform {
constructor(chunkSize, options) {
super(options);
this.chunkSize = chunkSize;
this.buffer = Buffer.alloc(0);
}
_transform(chunk, encoding, callback) {
this.buffer = Buffer.concat([this.buffer, chunk]);
while (this.buffer.length >= this.chunkSize) {
this.push(this.buffer.subarray(0, this.chunkSize));
this.buffer = this.buffer.subarray(this.chunkSize);
}
callback();
}
_flush(callback) {
if (this.buffer.length > 0) this.push(this.buffer);
callback();
}
}This is simple and correct for modest data rates. For very high-volume byte parsing, repeated Buffer.concat() can become the hot allocation site. A buffer list or ring buffer reduces copying when profiling shows that this section is responsible for the cost.
A join transform moves in the other direction by combining several input chunks into one output chunk -
class BatchAccumulator extends Transform {
constructor(batchSize, options) {
super({ ...options, objectMode: true });
this.batchSize = batchSize;
this.batch = [];
}
_transform(obj, encoding, callback) {
this.batch.push(obj);
if (this.batch.length >= this.batchSize) {
this.push(this.batch);
this.batch = [];
}
callback();
}
_flush(callback) {
if (this.batch.length > 0) this.push(this.batch);
callback();
}
}This transform emits no output until the batch is full or the stream ends. That delay is still a valid Transform behavior.
Stateful Binary Parsing
Length-prefixed protocols are a good test of transform state because the parser has to remember where it is. Each message starts with a 4-byte big-endian unsigned length, followed by that many body bytes. The parser must handle every split point - a header split across chunks, a body split across chunks, multiple messages in one chunk, and EOF during a partial message.
class LengthPrefixedParser extends Transform {
constructor(options) {
super({ ...options, readableObjectMode: true });
this.buffer = Buffer.alloc(0);
this.expectedLength = null;
}
_transform(chunk, encoding, callback) {
this.buffer = Buffer.concat([this.buffer, chunk]);
this._parseAvailable();
callback();
}
_parseAvailable() {
while (true) {
if (this.expectedLength === null) {
if (this.buffer.length < 4) return;
this.expectedLength = this.buffer.readUInt32BE(0);
this.buffer = this.buffer.subarray(4);
}
if (this.buffer.length < this.expectedLength) return;
this.push(this.buffer.subarray(0, this.expectedLength));
this.buffer = this.buffer.subarray(this.expectedLength);
this.expectedLength = null;
}
}
_flush(callback) {
if (this.expectedLength !== null || this.buffer.length > 0) {
callback(new Error("Incomplete length-prefixed message"));
return;
}
callback();
}
}The loop is not guarded only by this.buffer.length >= 4 once a body length has already been read. That detail prevents a real bug. After a 4-byte header says the body is 2 bytes, the body may arrive as two 1-byte chunks. The parser must keep checking the body state even when fewer than 4 bytes are buffered.
EOF is also part of the state machine. A partial header or partial body is not a final message in this protocol, so _flush() reports it as an error.
The Chunk Edge Problem
Stream chunks are transport units, not application records. A file stream, socket, HTTP body, gzip stream, or upstream transform can split data wherever its own buffering allows. Newlines, JSON documents, CSV rows, and binary frames get no special treatment unless your code gives them one.
Most parsers follow the same broad shape -
class Parser extends Transform {
constructor(options) {
super(options);
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
let unit;
while ((unit = this.extractCompleteUnit())) {
this.push(unit.data);
}
callback();
}
}The missing details are the actual parser - what counts as complete, how much state you need, and what EOF means. Delimiter-based formats often need a string buffer. Binary formats usually need a Buffer and explicit state variables. Text formats with quoting or escaping need more state than split("\n").
A deliberately limited CSV parser should say exactly what it does -
class NaiveCSVParser extends Transform {
constructor(options) {
super({ ...options, readableObjectMode: true });
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
const lines = this.buffer.split("\n");
this.buffer = lines.pop();
for (const line of lines) this.push(line.split(","));
callback();
}
_flush(callback) {
if (this.buffer.length > 0) this.push(this.buffer.split(","));
callback();
}
}This handles rows split across chunks. It does not handle quoted commas, escaped quotes, quoted newlines, byte order marks, comments, or dialect differences. A production CSV transform needs a real CSV state machine or a maintained parser library.
Push, Write, and Backpressure
this.push(chunk) writes to the readable side of the transform. It returns a boolean, but that boolean is a signal after the chunk has already been accepted into the readable buffer.
_transform(chunk, encoding, callback) {
const canAcceptMoreReadableData = this.push(processChunk(chunk));
if (!canAcceptMoreReadableData) {
// The readable side crossed its threshold.
}
callback();
}In a typical Transform, you still call the callback for the current chunk. The base class coordinates the next step. If the readable side remains full, Node stops calling _transform() for later chunks until data is consumed from the readable side.
That does not remove writable-side backpressure. Upstream producers still call write() on the transform's writable side, and write() can return false when the writable-side buffer reaches its own highWaterMark. If a producer ignores that return value and keeps writing, the writable buffer can grow even while the transform is paused by readable-side pressure.
The two signals answer different questions. write() returning false tells the upstream producer to pause. push() returning false tells the transform that downstream readable capacity is full.
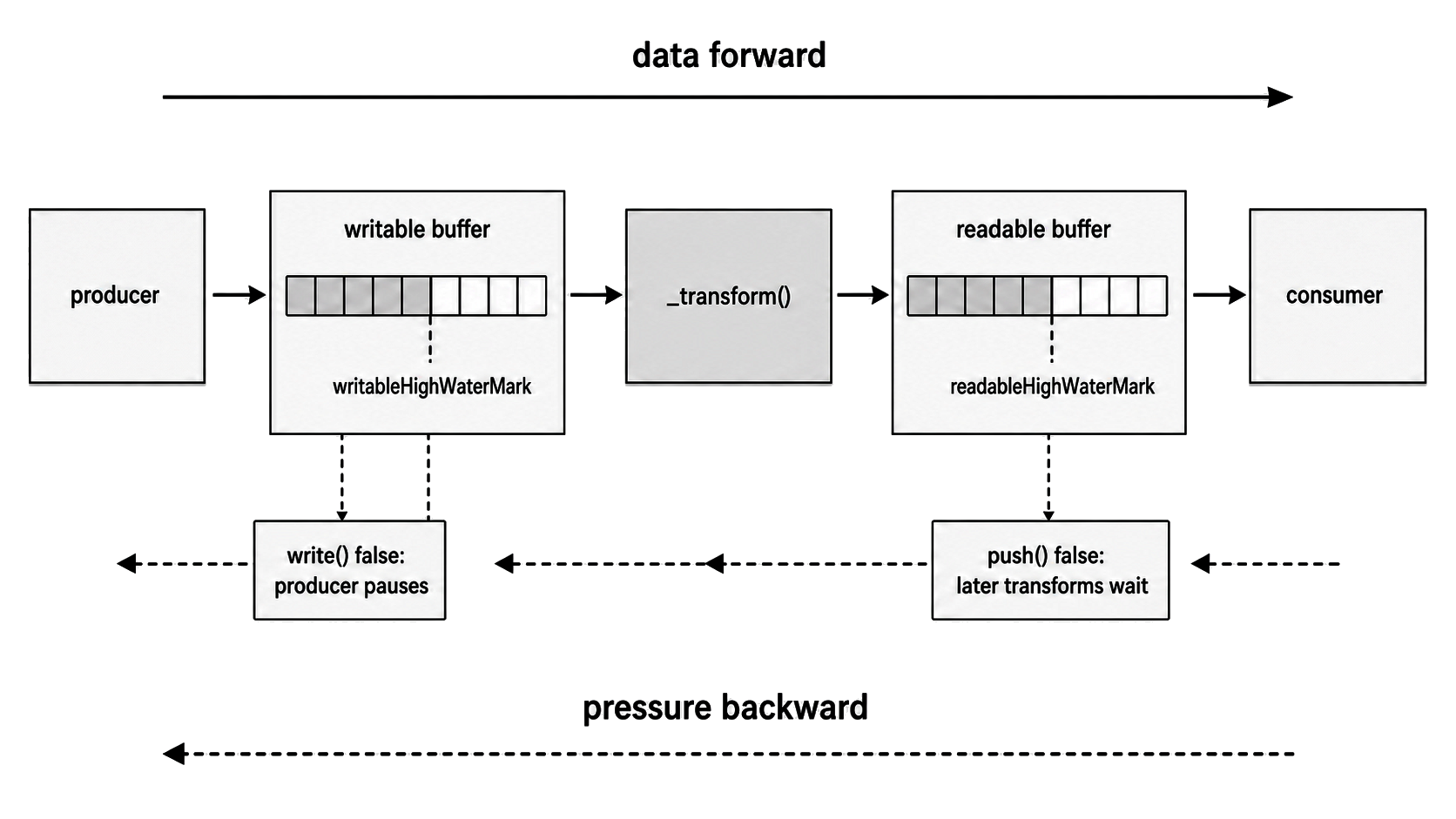
Figure 3 - Backpressure crosses a Transform through two separate buffers. Downstream readable pressure can stop later transform work while upstream write pressure tells producers when to pause.
You can see the split with a transform configured for object mode and a tiny readable buffer. The first writes may return true because the writable side has room, while _transform() stops after the readable side fills -
const t = new Transform({
readableObjectMode: true,
writableObjectMode: true,
readableHighWaterMark: 2,
writableHighWaterMark: 20,
transform(chunk, encoding, callback) {
console.log("transform", chunk, this.push(chunk));
callback();
},
});
for (let i = 0; i < 10; i += 1) {
console.log("write", i, t.write(i));
}With no readable consumer attached, the transform reaches its readable threshold after two pushed objects. Later writes can still enter the writable-side buffer until that side reaches its own threshold. Once a consumer starts reading, the readable buffer drains and the transform resumes processing the queued writes.
That is why a transform can look idle even after upstream writes have already returned. The input is not lost. It is waiting in the internal queue, and that queue is blocked by readable-side pressure. Public properties such as readableLength, readableHighWaterMark, writableLength, writableHighWaterMark, and writableNeedDrain are safer debugging tools than private fields such as _readableState.
For bounded one-to-many transforms, pushing all output for the current input is usually fine. For unbounded expansion, do not precompute a huge array and push it in a loop. Split the operation into smaller input chunks, use an async-generator transform in pipeline(), or design a custom stream with an explicit output queue and size bound.
PassThrough
PassThrough is the smallest built-in example of this contract. It is a Transform whose _transform() forwards the input unchanged.
import { PassThrough } from "node:stream";
const passthrough = new PassThrough();Because it does not alter the data, it is useful for observing a pipeline without changing that pipeline's output -
import { pipeline } from "node:stream/promises";
const tap = new PassThrough();
tap.on("data", (chunk) => {
console.log("passing through", chunk.length, "bytes");
});
await pipeline(source, tap, destination);A minimal implementation is just the callback shorthand -
class MyPassThrough extends Transform {
_transform(chunk, encoding, callback) {
callback(null, chunk);
}
}The second callback argument is forwarded to push() when the first argument is falsy.
Transform vs Duplex
Use Transform when written chunks determine readable chunks. Compression, encryption, parsing, formatting, filtering, mapping, batching, and serialization all belong here.
Use Duplex when the two directions are independent. TCP sockets, IPC channels, proxy connections, and bidirectional protocols belong here.
A gzip stream is a transform -
import { createGzip } from "node:zlib";
const gzip = createGzip();
input.pipe(gzip).pipe(output);The compressed output depends on the uncompressed input.
A TCP socket is a duplex channel -
import { connect } from "node:net";
const socket = connect(3000, "localhost");
socket.write("request");
socket.on("data", (chunk) => {
console.log("response -", chunk);
});The data you read is controlled by the peer. Your writes may cause that peer to respond, but the stream object does not transform your input into that output.
There are edge cases where a raw Duplex has shared configuration across independent directions. A bidirectional encrypted protocol might encrypt outbound bytes and decrypt inbound bytes on the same object. In application pipelines, two separate transforms are usually easier to compose and test.
Production Transform Patterns
Production transforms are usually small state machines with clear policies. Counting logical lines, for example, means handling the final line even if the input does not end with \n -
class LineCounter extends Transform {
constructor(options) {
super({ ...options, readableObjectMode: true });
this.lines = 0;
this.bytes = 0;
this.pending = "";
}
_transform(chunk, encoding, callback) {
const text = chunk.toString();
this.bytes += Buffer.byteLength(text);
this.pending += text;
const parts = this.pending.split("\n");
this.pending = parts.pop();
this.lines += parts.length;
callback();
}
_flush(callback) {
if (this.pending.length > 0) this.lines += 1;
this.push({ lines: this.lines, bytes: this.bytes });
callback();
}
}This reports one line for "abc" and one line for "abc\n". If your metric should count newline delimiters instead, name it that way.
A rate limiter uses the callback gate directly. By delaying callbacks, it slows input processing -
class RateLimiter extends Transform {
constructor(bytesPerSecond, options) {
if (bytesPerSecond <= 0) {
throw new RangeError("bytesPerSecond must be positive");
}
super(options);
this.bytesPerSecond = bytesPerSecond;
this.tokens = bytesPerSecond;
this.lastRefill = Date.now();
}
_transform(chunk, encoding, callback) {
this._refillTokens();
const wait = Math.max(0, chunk.length - this.tokens);
setTimeout(() => {
this.tokens = Math.max(0, this.tokens - chunk.length);
callback(null, chunk);
}, (wait / this.bytesPerSecond) * 1000);
}
_refillTokens() {
const now = Date.now();
const elapsed = (now - this.lastRefill) / 1000;
this.tokens = Math.min(
this.bytesPerSecond,
this.tokens + elapsed * this.bytesPerSecond
);
this.lastRefill = now;
}
}This is an illustrative token bucket, not a full traffic shaper. It does not know downstream capacity, it does not split oversized chunks, and timer precision depends on event loop load.
A deduplicator uses the same stateful pattern in object mode -
class Deduplicator extends Transform {
constructor(keyField, options) {
super({ ...options, objectMode: true });
this.keyField = keyField;
this.seen = new Set();
}
_transform(obj, encoding, callback) {
const key = obj[this.keyField];
if (!this.seen.has(key)) {
this.seen.add(key);
this.push(obj);
}
callback();
}
}For unbounded streams, seen is unbounded too. Production versions usually need a bounded cache, TTL, window, database lookup, or upstream guarantee about input size.
These examples all follow the same contract. Consume input chunks, keep the required state, and emit zero or more output chunks without pretending chunk boundaries are record boundaries.
Error Handling and Cleanup
_transform() and _flush() report implementation errors through their callback -
_transform(chunk, encoding, callback) {
try {
const result = this.process(chunk);
callback(null, result);
} catch (err) {
callback(err);
}
}For asynchronous work, still call the callback exactly once. Node does not treat a returned promise as the completion signal for _transform() in Node v24.
_transform(chunk, encoding, callback) {
this.processAsync(chunk).then(
(result) => callback(null, result),
(err) => callback(err)
);
}Do not write an async _transform() that omits the callback. The stream will wait for a callback that never arrives, and the pipeline can hang.
Cleanup belongs in _destroy(err, callback) when the transform owns timers, handles, temporary files, or external resources -
_destroy(err, callback) {
clearTimeout(this.timer);
callback(err);
}Do not leave stream errors unhandled. For composed streams, prefer pipeline() because it forwards errors and tears down the chain -
import { pipeline } from "node:stream/promises";
await pipeline(source, transform, destination);For a standalone transform that is not inside pipeline() or finished(), attach an error listener -
transform.on("error", (err) => {
console.error("transform failed -", err);
});An unhandled error event from a raw stream is still a process-level failure.
Inline and Generator Transforms
Small transforms do not need a subclass -
import { Transform } from "node:stream";
const uppercase = new Transform({
transform(chunk, encoding, callback) {
callback(null, chunk.toString().toUpperCase());
},
});For simple pipeline-local transforms, an async generator can be cleaner -
import { pipeline } from "node:stream/promises";
await pipeline(
source,
async function* uppercase(chunks) {
for await (const chunk of chunks) {
yield chunk.toString().toUpperCase();
}
},
destination
);The generator participates in pipeline() error handling and backpressure. Use a class when you need a reusable stream type, constructor options, explicit _flush(), or custom cleanup.
Performance and Tests
Transform overhead is real, but it is usually not the first bottleneck. Measure before replacing stream abstractions. Small chunks, repeated Buffer.concat(), object-mode allocation, JSON parsing, and downstream I/O are the usual suspects.
Batching reduces per-chunk overhead -
for await (const batch of batchedStream) {
for (const obj of batch) {
process(obj);
}
}Testing transforms should cover chunk boundaries, EOF behavior, invalid input, object modes, and backpressure.
import assert from "node:assert/strict";
import { Readable, Transform, Writable } from "node:stream";
import { pipeline } from "node:stream/promises";
const upper = new Transform({
transform(chunk, encoding, callback) {
callback(null, chunk.toString().toUpperCase());
},
});
const output = [];
await pipeline(
Readable.from(["hello", "world"]),
upper,
new Writable({
write(chunk, encoding, callback) {
output.push(chunk.toString());
callback();
},
})
);
assert.deepEqual(output, ["HELLO", "WORLD"]);A better backpressure test observes stream signals, not just elapsed time -
const slow = new Writable({
highWaterMark: 1,
write(chunk, encoding, callback) {
setTimeout(callback, 25);
},
});
assert.equal(slow.write("a"), false);
assert.equal(slow.writableNeedDrain, true);
slow.end();Elapsed time can prove that a slow destination was slow. It does not prove that a producer honored write() returning false, that drain was awaited, or that readable-side pressure stopped later _transform() calls.
Transform streams are small state machines with two buffers around them. Correct implementations come down to three commitments - every chunk is acknowledged exactly once, every partial record has an EOF policy, and every pressure signal has an owner.
Related Reading
- Previous - Node.js Writable Streams - Backpressure, drain, and Internal Buffering
- Next - Node.js Stream Pipeline - pipe(), pipeline(), Errors, and Cleanup