Writable Streams: Backpressure, drain, and Custom Sinks
A Writable stream is the receiving side of a chunked data flow. Some code calls write(chunk), the stream accepts that chunk, and the stream eventually passes it to a destination such as a file, socket, compression stream, database writer, or custom sink.
The key detail is the return value of write(). It tells the producer whether the Writable side is keeping up or whether too much data is already queued.
What a Writable Stream Is
Readable streams sit on the producer side. They create or deliver chunks over time. Writable streams sit on the other side. They receive those chunks and turn them into some effect outside the stream - bytes written to disk, bytes sent over a socket, compressed output, database rows, log entries, or anything else your destination needs.
That destination is often slower than the code producing chunks. Node does not block the event loop until the destination catches up. Instead, the Writable stream accepts chunks into an internal queue and uses the return value of write() to tell the producer what to do next.
When write() returns true, the producer can keep going. When it returns false, the producer should stop writing for now and wait for drain.
That feedback path is backpressure. Without it, a fast producer can keep adding chunks faster than the destination can process them. The stream keeps accepting those chunks, and memory usage keeps growing.
The Writable Stream Class
A Writable stream is an EventEmitter, just like a Readable stream. It emits events because writes finish asynchronously. The JavaScript call that queues a chunk usually returns before the file system, network stack, compression algorithm, or custom destination has finished handling that chunk.
Application code usually works with the public methods - write() and end(). Stream implementers provide the internal methods - _write(), and sometimes _writev(), _final(), _construct(), or _destroy(). Those hooks let the stream manage buffering, completion, backpressure, cleanup, and errors around the destination.
The option you will tune most often is highWaterMark. For a Writable stream, this is the threshold where write() starts returning false. It is not a hard memory cap. In Node v24, the default is 65536 bytes, or 64 KiB, for byte-mode Writable streams and 16 objects for object-mode streams. Older Node.js versions used a 16 KiB byte-mode default.
import { Writable } from "node:stream";
const writable = new Writable({
highWaterMark: 8192,
});This stream is only configured. A real custom Writable also needs a write option or an implementation of _write(), and sometimes related hooks. The threshold still affects the stream either way. Once the queued writable data reaches or passes highWaterMark, write() returns false, but the stream still accepts the chunk that crossed the threshold. The return value is the stream asking the producer to pause.
In objectMode, the same threshold is counted in objects instead of bytes -
const objectWritable = new Writable({
objectMode: true,
highWaterMark: 50,
});Here a chunk might be a database row, parsed log entry, JSON document, or any other JavaScript value. A highWaterMark of 50 means 50 objects can be queued before the stream starts asking the producer to pause. It does not mean 50 bytes.
Two string-related options affect what reaches _write(). By default, decodeStrings is true, so strings passed to write() are converted to Buffer objects before _write() receives them. If decodeStrings is false, strings are passed through as strings -
const stringWritable = new Writable({
decodeStrings: false,
});When string decoding is enabled, defaultEncoding controls the encoding used for that conversion. The default is "utf8", which is usually what you want for text streams.
The emitClose option controls whether the stream emits close after it is destroyed. The default is true, and most streams should keep it that way. Many callers use close to observe resource cleanup, so turning it off should be a deliberate choice.
Those options define the stream's behavior, but most of what you will observe day to day comes through events.
Events on Writable Streams
Writable stream events tell you where the stream is in its lifecycle. Some events mean normal progress, some mean cleanup, and drain carries the backpressure signal back to the producer.
The drain event fires after write() has returned false and the stream has processed enough queued data for the producer to continue. Treat it as a resume signal.
function writeData(writable, data, resumeProducing) {
if (!writable.write(data)) {
writable.once("drain", resumeProducing);
}
}The producer writes a chunk, sees false, pauses its own work, and registers a one-time listener. When drain fires, the stream is no longer asking the producer to stay paused. A blocking write() would freeze the event loop while the destination catches up. drain keeps that flow control asynchronous.
The finish event belongs to the normal end path. It fires after end() has been called, all buffered data has been written, and _final() has completed if the stream implements it.
writable.on("finish", () => {
console.log("All data written");
});
writable.write("some data");
writable.end();After end() is called, no more chunks should be written. A later write() is a write-after-end error. In current Node.js releases, that error is reported through the write callback and, depending on timing and listener setup, through the stream error path.
The close event is different from finish. It means the stream and its underlying resources have closed. On a normal successful end, streams that emit close usually emit it after finish. Error and destroy paths can emit close without finish, and emitClose: false suppresses close.
writable.on("close", () => {
console.log("Stream closed");
});The common lifecycle paths look like this -
normal end - write callback(s) -> _final() -> finish -> close
error path - write callback(error) -> error -> close
destroy - destroy(error) -> error -> closeThe error event reports failures from the writable side. The destination might run out of disk space, a socket might close, the data might be invalid for the sink, or the stream might be used after it has ended or been destroyed. As with Readable streams, an unhandled stream error is thrown and can crash the process.
writable.on("error", (err) => {
console.error("Write error", err);
});The pipe event fires when a Readable stream is piped into this Writable stream. Its argument is the source Readable. The matching unpipe event fires when that source is detached. These events are mostly useful for instrumentation and debugging.
writable.on("pipe", (src) => {
console.log("Readable attached");
});Once these events are clear, backpressure becomes easier to follow. The producer writes, the Writable queues, the destination consumes, and drain tells the producer when it can resume.
Understanding Backpressure
Backpressure shows up whenever a producer can generate chunks faster than the destination can consume them. A hand-written file copy is enough to see the problem -
import { createReadStream, createWriteStream } from "node:fs";
const readable = createReadStream("input.dat");
const writable = createWriteStream("output.dat");
readable.on("data", (chunk) => {
writable.write(chunk);
});This code moves chunks from input.dat to output.dat, but it ignores the destination's capacity. If the source can produce 100 MB per second and the destination can write only 50 MB per second, the extra 50 MB per second accumulates in the Writable stream's buffer. After one second, that is roughly 50 MB. After ten seconds, it is roughly 500 MB. The mismatch keeps turning into memory pressure.
The fix is to use write() as feedback. When it returns false, pause the producer and resume it from drain -
readable.on("data", (chunk) => {
if (!writable.write(chunk)) {
readable.pause();
writable.once("drain", () => readable.resume());
}
});Now the destination controls the pace. The Readable stream stops emitting data while the Writable side drains its queue, then resumes when the destination has caught up enough. This pause and resume loop is also why pipe() exists. It connects a Readable to a Writable and handles ordinary stream-to-stream backpressure for you.
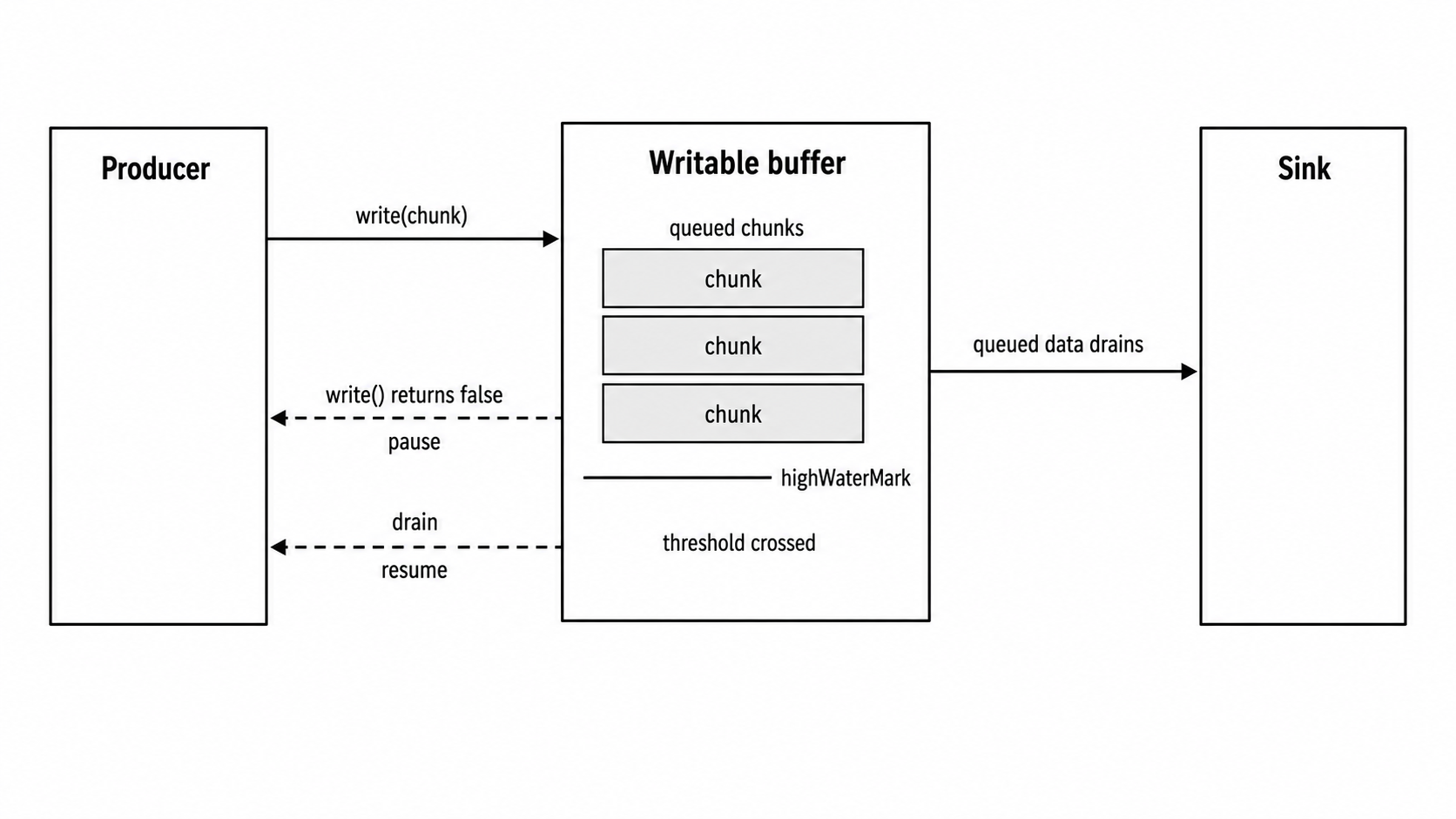
Figure 3.1 - Backpressure is a feedback loop. write() accepts the chunk that crosses the threshold, returns false, and drain later tells the producer it can continue.
Inside the Writable stream, the same idea is just a queue. A call to write() either starts a write immediately, if the destination is idle, or adds the chunk to pending writes. The stream then compares the queued amount with highWaterMark and returns true or false.
Application code should rely on that public behavior instead of private _writableState fields. Node's internal queue implementation has changed over time. The stable parts are the public ones - writes preserve order, writableLength exposes the current queued size, writableHighWaterMark exposes the configured threshold, and write() returns false when the stream wants the producer to pause.
A simplified model looks like this -
write(chunk) {
this.buffer.push(chunk);
this.length += chunk.length;
if (!this.writing) this._doWrite();
return this.length < this.highWaterMark;
}For byte streams, length is based on chunk sizes. For object-mode streams, it is based on object count. The _write() implementation and the destination's speed decide how quickly that length falls again.
The callback passed to _write() is the handoff point. Until the implementation calls it, the stream treats that write as unfinished and does not move to the next queued chunk.
_doWrite() {
const chunk = this.buffer.shift();
this.writing = true;
this._write(chunk, (err) => {
this.writing = false;
if (err) this.emit("error", err);
else this._doWrite();
});
}Real streams track more state than this sketch - needDrain, ending state, destruction state, callbacks, batching paths, and more. The useful mental model stays the same. The producer can add to the queue quickly. The destination removes from it at its own pace. write() and drain connect those two speeds.
That loop only works if the producer listens. If a program writes one million 1 KiB chunks to a slow destination without checking the return value, it can enqueue about 1 GiB of chunk data for that stream, plus stream bookkeeping overhead. With many streams or many concurrent requests, that cost multiplies quickly.
This is why highWaterMark is a tuning threshold, not a safety guard. A lower threshold creates more frequent backpressure signals and may reduce throughput through constant pausing and resuming. A higher threshold allows more queued data and may improve throughput for some destinations, but it also increases memory exposure when many streams are active.
For most byte streams, the modern 64 KiB default is a good starting point. If your code supports releases before Node.js 22.0, remember that the older byte-mode default was 16 KiB.
The rule is simple - after write() returns false, stop producing for that Writable until drain fires.
Internal Buffering
Writable buffering is the queue between the producer and the destination. The producer is the code calling write(). The destination is the code reached through _write() or _writev(). When the destination is busy, the queue holds later chunks so write order is preserved.
The exposed queue size is writableLength. In byte mode, it is measured in bytes. In object mode, it is measured in objects. Node compares that value with writableHighWaterMark to decide whether write() should return true or false.
Once write() has returned false, Node records that the stream should emit drain later. When buffered writes have been processed far enough, drain is emitted and the producer can resume.
if (this.length >= this.highWaterMark) {
this.needDrain = true;
return false;
}That small condition is the visible backpressure signal. It does not block additional writes. If the application keeps calling write() after false, the stream keeps accepting chunks and memory keeps growing.
This design gives applications control. Some producers pause, some drop data, and some use their own queueing policy. For ordinary data movement, the correct default is to pause.
The buffer also has overhead beyond the chunk contents. Each pending write carries metadata such as the chunk, encoding, callback, and internal bookkeeping. With a huge number of tiny writes, that overhead becomes noticeable. Batching small writes into larger units can improve both throughput and memory behavior.
The stream API provides cork() and uncork() for that kind of burst. While a stream is corked, writes are held back. When it is uncorked, Node flushes them. If the stream implements _writev(), the flush can be passed as a batch.
writable.cork();
writable.write("line 1\n");
writable.write("line 2\n");
writable.write("line 3\n");
writable.uncork();Without cork(), those writes may reach _write() separately. With cork(), they can be grouped, which reduces I/O overhead when the destination benefits from batching. This is most useful in libraries and protocol implementations that generate many small chunks. Typical application code usually gets enough buffering from the stream itself.
cork() can be nested. Each call increments an internal counter, and the stream flushes only after the same number of uncork() calls.
Implementing Custom Writable Streams
A custom Writable exposes the stream contract directly. It receives one chunk, sends it to a destination, and calls a callback when that destination has accepted the chunk or failed.
The smallest implementation extends Writable and implements _write() -
import { Writable } from "node:stream";
class NullWritable extends Writable {
_write(chunk, encoding, callback) {
callback();
}
}This behaves like /dev/null. It accepts chunks and completes each write immediately. An in-memory sink differs only in what it does before calling the callback.
class ArrayWritable extends Writable {
constructor(options) {
super(options);
this.data = [];
}
_write(chunk, encoding, callback) {
this.data.push(chunk);
callback();
}
}Asynchronous destinations make the callback more important. The stream does not move to the next buffered chunk until the callback for the current chunk fires.
class AsyncWritable extends Writable {
_write(chunk, encoding, callback) {
setTimeout(() => {
console.log("Wrote", chunk.toString());
callback();
}, 100);
}
}That delayed callback is how a custom Writable matches the destination's speed. If a database write, network send, or file operation takes longer, the stream's queue stays blocked for longer, and upstream backpressure follows from that delay.
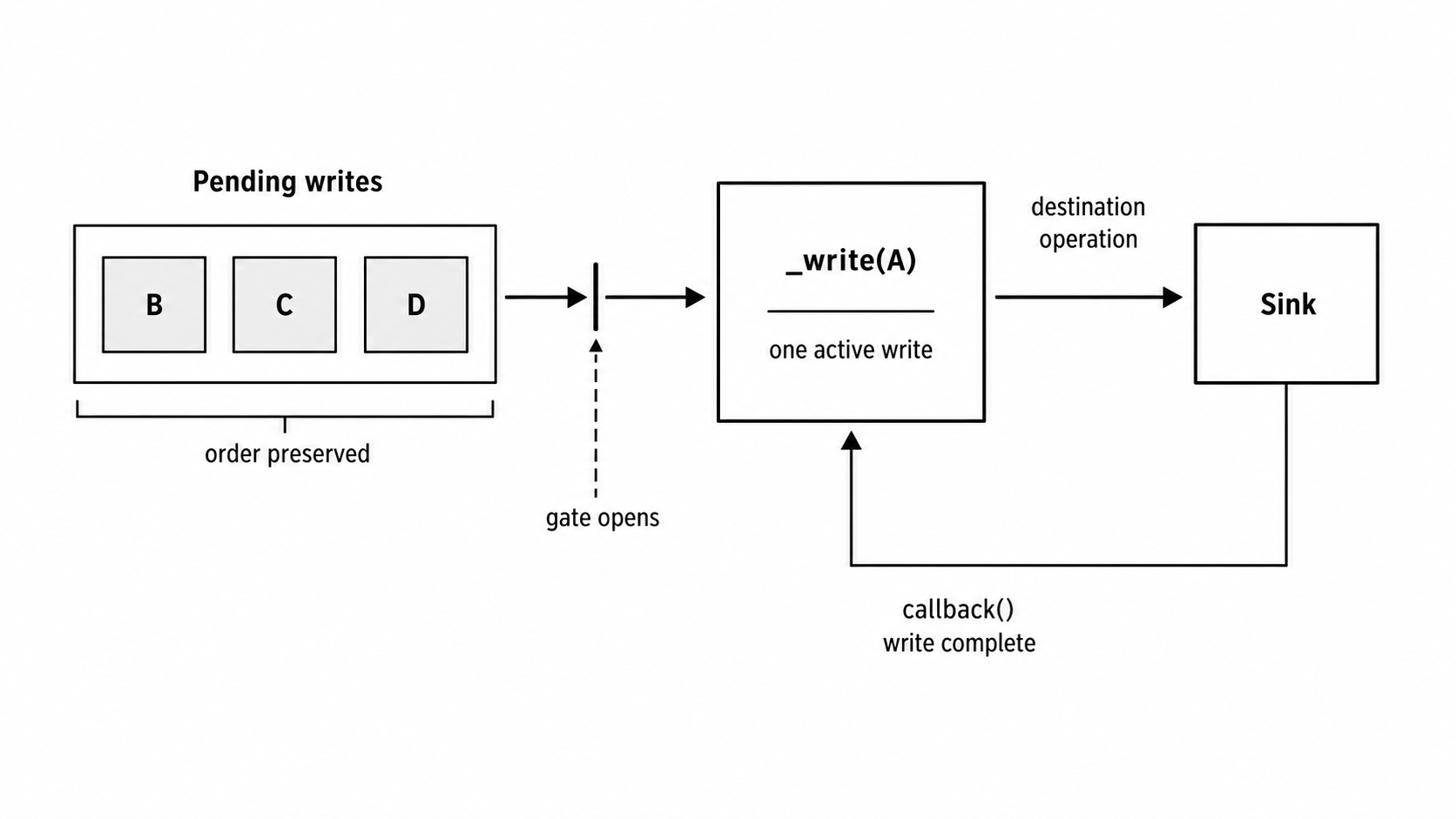
Figure 3.2 - The _write() callback controls when the next queued chunk can run. Until the active write completes, later chunks stay queued in order.
Failures use the same callback -
class ErrorWritable extends Writable {
_write(chunk, encoding, callback) {
const bad = chunk.toString().includes("bad");
callback(bad ? new Error("Invalid data") : undefined);
}
}Passing an error causes the stream to emit error and enter an errored state. Buffered writes are discarded, and later writes are rejected through the stream's error state.
The optional _writev() method handles a batch of buffered writes. Use it when the destination has a real batch operation.
class BatchWritable extends Writable {
_writev(chunks, callback) {
const data = Buffer.concat(chunks.map((c) => c.chunk));
console.log("Batch write", data.length, "bytes");
callback();
}
}The chunks array contains objects with chunk and encoding properties. Without _writev(), Node falls back to calling _write() for each buffered chunk.
The _final() hook runs on the normal end path, after all buffered writes have completed and before finish is emitted. Use it for final data or cleanup that must happen before the stream is considered finished.
class CleanupWritable extends Writable {
_write(chunk, encoding, callback) {
callback();
}
_final(callback) {
console.log("Finalizing...");
callback();
}
}The callback in _final() is required. If it never fires, finish never fires.
When the destination needs asynchronous setup, implement _construct(callback). Node calls it before _write(), so early writes wait until initialization completes or fails. Pair it with _destroy(err, callback) when the stream owns a resource that must be released on errors or cancellation.
For a log writer backed by a file descriptor, start with the resource fields -
import { close, open, write as fsWrite } from "node:fs";
class LogWritable extends Writable {
constructor(filename, options) {
super(options);
this.filename = filename;
this.fd = null;
}
}Then isolate the resource setup in _construct() -
_construct(callback) {
open(this.filename, "a", (err, fd) => {
if (err) return callback(err);
this.fd = fd;
callback();
});
}Once _construct() succeeds, _write() can assume the file descriptor is available -
_write(chunk, encoding, callback) {
const line = `[${new Date().toISOString()}] ${chunk}\n`;
fsWrite(this.fd, line, callback);
}The normal end path and early teardown path can share the same close logic -
_final(callback) {
this._closeFd(callback);
}
_destroy(err, callback) {
this._closeFd((closeErr) => callback(err ?? closeErr));
}The close helper makes the operation safe to call more than once -
_closeFd(callback) {
if (this.fd === null) return callback();
const fd = this.fd;
this.fd = null;
close(fd, callback);
}In the full log-writer shape, _construct() opens the file, _write() formats and writes each chunk, _final() closes the descriptor during a normal end, and _destroy() closes it if the stream is torn down early. Repeated fs.write() calls are safe in this design because the Writable stream does not call the next _write() until the previous callback has fired.
Custom Writable streams are useful because application-specific destinations can still participate in the standard stream lifecycle and backpressure behavior.
Writing Correctly
For direct writes, use the same rule the stream uses internally - always check write()'s return value. If it returns false, pause the source and wait for drain before continuing.
import { createReadStream, createWriteStream } from "node:fs";
const reader = createReadStream("input.txt");
const writer = createWriteStream("output.txt");
reader.on("data", (chunk) => {
if (!writer.write(chunk)) reader.pause();
});
writer.on("drain", () => reader.resume());
reader.on("end", () => writer.end());This is the minimal flow-control version. It keeps the backpressure path visible, but it leaves out error handling and completion coordination.
For normal stream-to-stream work, prefer pipeline(). It wires backpressure, completion, and error teardown for you.
import { createReadStream, createWriteStream } from "node:fs";
import { pipeline } from "node:stream/promises";
await pipeline(
createReadStream("input.txt"),
createWriteStream("output.txt")
);The production default is straightforward - use pipeline() for stream chains. For non-stream producers, check write(), wait for drain when needed, and observe completion with finished().
When no more chunks are coming, call end(). You can pass the final chunk directly -
writer.end("final chunk");That is equivalent to writing the final chunk and then ending -
writer.write("final chunk");
writer.end();After end(), the stream finishes remaining buffered writes, runs _final() if present, and emits finish. Calling write() after that is a write-after-end error.
writer.on("error", (err) => {
console.error(err.code);
});
writer.end();
writer.write("more data", (err) => {
if (err) console.error(err.code);
});The error code is ERR_STREAM_WRITE_AFTER_END. Depending on timing, you may see the callback error, an error event, or both. Do not rely on catching it synchronously. The usual cause is coordination - one asynchronous path calls end() while another still expects to write. Make end() run only after outstanding write callbacks have fired.
Manual cork() and uncork() are useful when you intentionally generate many small writes in one burst.
writer.cork();
try {
for (let i = 0; i < 1000; i++) {
writer.write(`line ${i}\n`);
}
} finally {
writer.uncork();
}The finally block makes sure the stream is uncorked even if the loop throws. In ordinary application code, this pattern is uncommon. It is more often used by libraries that generate structured output, such as protocol encoders.
Non-stream producers need their own loop. An array writer can use finished() to observe the whole stream lifecycle and once() to wait for drain.
import { once } from "node:events";
import { finished } from "node:stream/promises";
async function writeArray(writable, array) {
const done = finished(writable);
done.catch(() => {});
try {
for (const item of array) {
if (!writable.write(item)) {
await Promise.race([once(writable, "drain"), done]);
}
}
writable.end();
await done;
} catch (err) {
writable.destroy(err);
throw err;
}
}This shape assumes the function owns the writable and is responsible for ending it. If another component owns the stream lifecycle, do not call end() inside the helper.
Node also provides Writable.toWeb() for adapting a Node Writable into a WHATWG WritableStream. That split belongs with the Web Streams material, but the backpressure signal still has to be carried across the adapter.
Under load, these patterns keep queued data bounded. A database import, for example, usually belongs in a pipeline - byte input, parser transform, object-mode writer.
class DatabaseWriter extends Writable {
constructor(db) {
super({ objectMode: true });
this.db = db;
}
_write(row, encoding, callback) {
this.db.insert(row).then(
() => callback(),
(err) => callback(err)
);
}
}The pipeline around it stays small -
await pipeline(
createReadStream(filename),
parseCSV(),
new DatabaseWriter(db)
);The parseCSV() call is deliberately hypothetical. A production parser should report malformed input through the stream error path. The writer may use promises internally, but _write() still has to call the callback Node passed to it. Stream implementer methods do not complete by returning a promise.
Peak Buffering Under Backpressure
Backpressure prevents unbounded growth only when producers respond to it. It also does not make highWaterMark a hard limit. The chunk that crosses the threshold is still accepted.
With a single producer that pauses immediately, peak writable-side buffering is roughly the threshold plus the largest chunk already handed to write() before the pause takes effect. With a 64 KiB threshold and 64 KiB chunks, plan around about 128 KiB rather than the whole file. If you hand the stream a 10 MiB chunk, that one write can exceed a 64 KiB threshold by itself.
Chunk size shapes the bound. Backpressure keeps the queue bounded only when producers honor the signal, and the bound depends on the chunks they write. Large chunks can be fine, but they should be intentional.
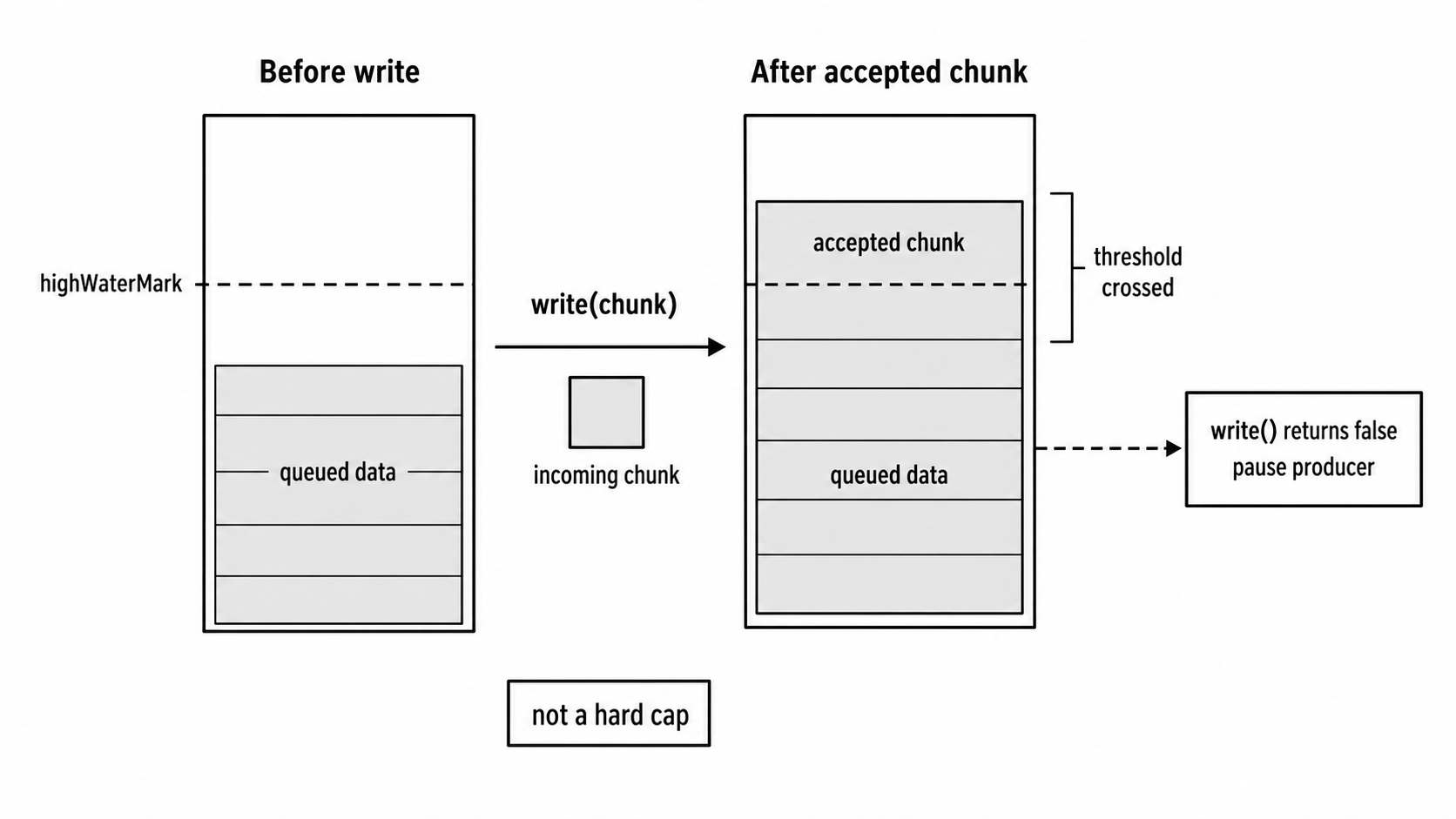
Figure 3.3 - highWaterMark is checked after accepting a chunk, so peak buffering can exceed the configured threshold by at least the chunk that crossed it.
Multiple producers need extra coordination. If ten producers all wait on the same drain event, they can all resume at once and push the queue over the threshold again. A shared queue, a single writer task, or another coordination primitive keeps the stream from becoming the only place where concurrency is handled.
Error Handling
The success path sends chunks to the destination. The failure path decides how pending writes are notified and how resources are closed.
Errors can come from the destination, invalid data, or invalid stream state. When _write(), _writev(), or _final() fails, the implementation passes the error to its callback. The stream responds by emitting error, entering an errored state, discarding buffered writes, and rejecting later writes through callbacks and stream state instead of a reliable synchronous exception.
class FailingWritable extends Writable {
_write(chunk, encoding, callback) {
callback(new Error("Write failed"));
}
}A write already queued behind the failing one receives the same failure -
const writable = new FailingWritable();
writable.on("error", (err) => {
console.error("Stream error", err.message);
});
writable.write("test");
writable.write("more", (err) => {
console.error(err.message);
});A later write after the stream has closed fails differently -
writable.on("close", () => {
writable.write("after close", (err) => {
console.error(err.code); // ERR_STREAM_DESTROYED
});
});If there is no error listener, the error is thrown and may crash the process. Pipeline-level error coordination belongs in the pipeline chapter. For direct Writable usage, attach an error handler to every stream you create or receive.
Writing after end() is a separate programming error. The stream reports ERR_STREAM_WRITE_AFTER_END through the write callback and may also emit error, depending on timing.
async function buggyWrite(writable) {
setTimeout(() => {
writable.write("async write", (err) => {
if (err) console.error(err.code);
});
}, 100);
writable.end();
}The fix is to coordinate the asynchronous write and end the stream only after that write has completed.
async function correctWrite(writable) {
await new Promise((resolve, reject) => {
setTimeout(() => {
writable.write("async write", (err) => {
if (err) reject(err);
else resolve();
});
}, 100);
});
writable.end();
}The destroy() method is the forceful shutdown path. Calling writable.destroy(err) puts the stream in a destroyed state, discards buffered writes, and emits error if an error was provided, followed by close.
writable.destroy(new Error("Aborted"));This is useful when an operation is cancelled, such as a user aborting a file upload. Buffered writes may still be pending when destruction begins, so treat it as immediate teardown rather than a graceful finish.
The destroyed property tells you whether a stream has been destroyed, but it does not tell you whether it has ended or errored. If you need to check whether a write is currently allowed, writable.writable is a better guard -
if (writable.writable) {
writable.write("data");
}Even this is only a guard. Another code path can end or destroy the stream between the check and the write, so shared writers still need lifecycle coordination.
Properties and Introspection
Writable streams expose state properties that are useful for debugging, monitoring, and generic stream utilities. Treat them as observations of stream state, not replacements for flow control.
writableLength reports how many bytes, or how many objects in object mode, are currently buffered on the writable side.
console.log(writable.writableLength);If the value approaches writableHighWaterMark, backpressure is close. It is also useful as a metric when you are checking whether a pipeline is accumulating data. Do not read it as total process memory. It does not include unrelated heap allocations, native memory, kernel socket buffers, or buffers held by other layers.
writableHighWaterMark exposes the configured threshold -
console.log(writable.writableHighWaterMark);writable is a boolean that indicates whether write() is currently allowed -
if (writable.writable) {
writable.write("data");
}writableEnded becomes true after end() has been called, even if finish has not fired yet.
console.log(writable.writableEnded);writableFinished becomes true after all writes have completed and finish has fired.
console.log(writable.writableFinished);writableCorked tells you how many cork() calls have not yet been matched by uncork().
writable.cork();
writable.cork();
console.log(writable.writableCorked); // 2writableObjectMode reports whether the stream was constructed in object mode.
console.log(writable.writableObjectMode);Most application code does not need all of these properties, but they are helpful when debugging stream behavior or writing utilities that accept arbitrary Writable streams.
Batching Small Writes with cork() and _writev()
Small writes can be expensive because each one carries stream bookkeeping and may map to an underlying I/O operation. cork() holds a burst temporarily, and uncork() flushes it. If the stream implements _writev(), Node can pass the buffered writes as one batch.
writable.cork();
writable.write("a");
writable.write("b");
writable.write("c");
writable.uncork();The batched implementation receives objects shaped like { chunk, encoding }, not raw chunks.
_writev(chunks, callback) {
const data = Buffer.concat(chunks.map((c) => c.chunk));
console.log("Batch write", data.length, "bytes");
callback();
}Without cork(), each chunk may be written separately as the previous _write() callback completes. For destinations such as files and sockets, reducing the number of I/O operations can improve throughput. For an in-memory array, batching may not help much. That is why _writev() is optional instead of part of the minimum Writable implementation.
objectMode Writable Streams
Byte streams measure backpressure in bytes. Object-mode streams measure it in objects. That changes what highWaterMark means and how you should choose it.
In object mode, a highWaterMark of 16 means 16 objects, regardless of each object's size in memory. Sixteen small rows and sixteen 10 MiB objects both count as 16 chunks. The threshold limits units of work in flight, not memory directly.
Object mode fits data-processing pipelines where each chunk is a logical record - a parsed log entry, a database row, a message, or a JSON document.
class RowWriter extends Writable {
constructor(db, options) {
super({ ...options, objectMode: true });
this.db = db;
}
_write(row, encoding, callback) {
this.db.insert(row).then(
() => callback(),
(err) => callback(err)
);
}
}Each write() passes a row object. The encoding parameter remains part of the method signature, but object chunks are not decoded as text or buffers.
A common pipeline converts byte input into object-mode output through a Transform. A JSON-lines parser does that by keeping incomplete text until a newline arrives, then pushing parsed objects on its readable side.
class JSONLineParser extends Transform {
constructor(options) {
super({ ...options, readableObjectMode: true });
this.buffer = "";
}
_transform(chunk, encoding, callback) {
this.buffer += chunk.toString();
this._emitLines(callback);
}
}The parsing work can stay in a helper -
_emitLines(callback) {
const lines = this.buffer.split("\n");
this.buffer = lines.pop();
try {
for (const line of lines) {
if (line.trim()) this.push(JSON.parse(line));
}
callback();
} catch (err) {
callback(err);
}
}The final incomplete line belongs in _flush() -
_flush(callback) {
try {
if (this.buffer.trim()) {
this.push(JSON.parse(this.buffer));
}
callback();
} catch (err) {
callback(err);
}
}Malformed input now reaches the stream error path through the transform callback. Production parsers should also cap the maximum buffered line size. Without that cap, a single unterminated line can grow without limit before _transform() sees a newline.
Object-mode streams are common in ETL systems, log processing, import and export jobs, and other pipelines where the useful unit is a structured record rather than a byte range.
The _final() Hook in Detail
_final() is the normal-end hook. It runs after all regular writes have completed and before finish is emitted. Use it when the stream has data or cleanup work that must happen at the end of a successful write sequence.
A batching Writable shows why the hook exists. The stream can flush full batches from _write() -
_write(chunk, encoding, callback) {
this.batch.push(chunk);
if (this.batch.length >= this.batchSize) {
this._flush(callback);
} else {
callback();
}
}The final partial batch has to be flushed from _final() -
_final(callback) {
if (this.batch.length > 0) {
this._flush(callback);
} else {
callback();
}
}The flush clears the batch before completing -
_flush(callback) {
const data = Buffer.concat(this.batch);
this.batch = [];
// write data to destination
callback();
}Without _final(), the last partial batch would be lost even though the stream would otherwise reach finish. This example uses Buffer.concat(), so it is for byte chunks, not object-mode rows.
The _final() callback is required, just like the _write() callback. If it is never invoked, finish never fires. If it receives an error, the stream emits error instead of finishing.
_final(callback) {
this.flushAsync().then(
() => callback(),
(err) => callback(err)
);
}Even when the final work uses promises internally, stream implementer methods do not complete by returning a promise. They complete when their callback is invoked.
Rate-Limited Custom Writable
A Writable can use delayed callbacks to pace upstream writers. A rate-limited byte stream, for example, can spend one token per byte and refill the bucket over time.
class RateLimitedWritable extends Writable {
constructor(dest, bytesPerSecond, options) {
super(options);
this.dest = dest;
this.bytesPerSecond = bytesPerSecond;
this.tokens = bytesPerSecond;
this.lastRefill = Date.now();
}
}Before each write, it refills tokens according to elapsed time.
_refillTokens() {
const now = Date.now();
const elapsed = (now - this.lastRefill) / 1000;
this.tokens = Math.min(
this.bytesPerSecond,
this.tokens + elapsed * this.bytesPerSecond
);
this.lastRefill = now;
}The write either passes through immediately or waits long enough to cover the missing tokens.
_write(chunk, encoding, callback) {
this._refillTokens();
if (this.tokens >= chunk.length) {
this.tokens -= chunk.length;
return this.dest.write(chunk, encoding, callback);
}
this._delayWrite(chunk, encoding, callback);
}The delayed branch updates lastRefill when the timer fires. Without that assignment, the next refill would count the waiting time twice and grant tokens for time already spent by the delayed write.
_delayWrite(chunk, encoding, callback) {
const wait = ((chunk.length - this.tokens) / this.bytesPerSecond) * 1000;
setTimeout(() => {
this.lastRefill = Date.now();
this.tokens = 0;
this.dest.write(chunk, encoding, callback);
}, wait);
}Chunks larger than bytesPerSecond still pass through. They spend the current bucket and wait for the missing portion. If you need a hard maximum chunk size, split large chunks before they reach this stream.
The callback is not invoked while the write is delayed. The Writable stream's internal queue is blocked during that delay, so upstream backpressure appears naturally while the destination is being paced.
Backpressure Across Multiple Writers
Backpressure is a per-stream signal, not a per-producer signal. When many producers write to one Writable, coordination has to happen above the stream API.
Each producer sees its own write() return value, but drain is broadcast to all listeners. If 100 producers pause on drain, all 100 can resume when it fires and immediately fill the buffer again. The stream then bounces between drained and full, which adds scheduling overhead and makes progress uneven.
A shared queue fixes this by giving the stream a single writer task. Producers enqueue work, and that writer task is the only code that calls write() and waits for drain. A semaphore or similar primitive can also limit how many producers are allowed to write concurrently.
In practice, the simplest design is often to avoid many direct concurrent writers to a single stream. If several sources need to feed one destination, use a higher-level abstraction such as a logging library, coordinated queue, or stream multiplexer that owns the interleaving policy.
Memory Profiling a Writable Stream
When memory grows during streaming, first check whether the Writable queue is growing. Start by checking whether the code is respecting backpressure.
const ok = writable.write(chunk);
if (!ok) {
console.log("Backpressure", writable.writableLength);
}If those messages appear and the producer does not pause, the stream is already showing you the problem. If the producer pauses and memory still grows, sample writableLength over time.
const interval = setInterval(() => {
console.log("Buffer size", writable.writableLength);
}, 1000);
interval.unref();A steadily increasing value means the writable-side queue is growing. That may be expected if the destination is genuinely slow, or it may mean the destination is stalled.
writableLength is only a stream queue metric. It does not include every object retained by callbacks, user code, native handles, kernel socket buffers, or destination-specific queues.
For heap-level investigation, use Node.js's built-in heap snapshot support. A heap snapshot is a serious diagnostic tool, not a harmless logging call. Generating one is synchronous, blocks the event loop, and can require about twice the current heap size.
import { writeHeapSnapshot } from "node:v8";
const snapshot = writeHeapSnapshot();
console.log("Heap snapshot written to", snapshot);Load the snapshot in Chrome DevTools and look for retained Buffer objects or stream-related bookkeeping objects. Large numbers of those objects point to the retention path you need to inspect.
The --trace-gc flag can also help in controlled diagnostics -
node --trace-gc app.jsIf garbage collection runs frequently while memory remains high, the program may be allocating faster than the runtime can reclaim. That pattern is consistent with an unbounded buffer. The output is noisy and can be expensive under load, so use it as a diagnostic flag rather than normal logging.
For production monitoring, track writable.writableLength. If it stays near writableHighWaterMark, the pipeline is hitting backpressure often and the destination is probably the bottleneck.
Combining Multiple Writables
Sometimes one chunk must be written to several destinations - a file and a database, multiple sockets, or several output channels. Writing to all of them manually looks simple, but backpressure becomes harder to interpret.
function writeToAll(writables, chunk) {
const results = writables.map((w) => w.write(chunk));
return results.every((r) => r === true);
}If one destination returns false and another does not, the producer still has to decide whether to pause. Waiting for all destinations slows the fast ones. Ignoring the slow one lets its buffer grow.
A fan-out Writable puts that policy in one place. First, wrap a destination write in a promise -
function writeOnce(dest, chunk, encoding) {
return new Promise((resolve, reject) => {
dest.write(chunk, encoding, (err) => {
if (err) reject(err);
else resolve();
});
});
}Ending uses the same callback-to-promise shape -
function endOnce(dest) {
return new Promise((resolve, reject) => {
dest.end((err) => {
if (err) reject(err);
else resolve();
});
});
}The aggregate stream waits for all destinations before completing its own write -
class FanOutWritable extends Writable {
constructor(destinations, options) {
super(options);
this.destinations = destinations;
}
_write(chunk, encoding, callback) {
Promise.all(
this.destinations.map((d) => writeOnce(d, chunk, encoding))
).then(() => callback(), callback);
}
}Ending and destroying are part of the same ownership decision -
_final(callback) {
Promise.all(this.destinations.map(endOnce)).then(
() => callback(),
callback
);
}
_destroy(err, callback) {
for (const dest of this.destinations) dest.destroy?.(err);
callback(err);
}This simplified aggregate writer assumes it owns the destination lifecycles, ends all destinations together, and aborts the aggregate on partial failure. It does not give each destination an independent backpressure policy. Its backpressure behavior comes from its callback. If any destination is slow, the fan-out stream's write remains incomplete, its buffer fills, and upstream producers see pressure.
Choosing highWaterMark
Choose highWaterMark based on chunk size, concurrency, memory budget, and destination latency. The modern byte-mode default of 64 KiB is a good starting point for most streams. It avoids excessive backpressure for common write patterns while keeping slow destinations from collecting too much buffered data. If you support Node.js versions before 22.0, remember that the older byte-mode default was 16 KiB.
If chunks are large, consider increasing the threshold to match. A stream receiving 1 MiB chunks will signal backpressure on every write when the threshold is much smaller than the chunk. A 2 MiB or 4 MiB threshold gives it room to queue a small number of chunks.
If memory is constrained, lower the threshold. In a container with strict limits, or on an embedded device, a 4 KiB or 8 KiB threshold may be more appropriate than the default.
If many streams run concurrently, multiply the threshold by the number of active streams to estimate threshold-sized buffering. One thousand HTTP response streams at 64 KiB each represent roughly 64 MiB of threshold-level writable buffering before chunk-size overshoot and bookkeeping overhead.
For object-mode streams, choose the threshold from measured object size, acceptable in-flight work, and target throughput. Database writes might tolerate 100 or 1000 rows in flight. A parser feeding heavier objects might need 10 or 50.
Make the value configurable when the right threshold depends on deployment. Start with defaults, measure throughput and memory, then adjust from real observations instead of from the constant alone.
The final point is the one to keep in your head while writing stream code - highWaterMark is a threshold, not a hard limit. Writable streams stay bounded under load only when producers treat write() as feedback instead of an unconditional enqueue. Use pipeline() for ordinary stream chains, use finished() when you manage direct writes, and make custom Writable implementations complete _write(), _writev(), _final(), _construct(), and _destroy() through callbacks. Those details are what keep a streaming program predictable when the destination slows down.
Related Reading
- Readable streams - Node.js Readable Streams - Flowing Mode, Paused Mode, and Backpressure
- Transform streams - Node.js Transform Streams - Duplex Streams, _transform, and Backpressure