Stream Foundations: Chunks, Buffers, and Backpressure
A stream moves data in pieces instead of forcing one operation to hold the whole input at once. A Readable produces chunks. A Writable accepts them. A Transform accepts chunks on one side, changes them, and emits new chunks on the other. A Duplex has both readable and writable sides, and those sides can move independently.
Once data is split into chunks, the questions change. The code has to decide who can produce the next chunk, how much data can wait in a queue, and what should happen when a later stage cannot keep up.
What Streams Are
Streams do not make memory disappear. They stop one operation from treating the full input as one JavaScript value, and they give each stage a way to slow the stage before it.
That slowdown can show up in a few ways. A Writable's write() call can return false. A later drain event can tell the writer to continue. A Readable can stop being asked for more data. pipeline() can coordinate the connected streams and clean them up when something fails.
The queue threshold is called highWaterMark. Byte streams measure it in bytes. Object-mode streams measure it in objects. Duplex and Transform streams have separate thresholds for their readable and writable sides because each side has its own queue.
In current Node v24, the generic byte-stream default is 64 KiB and the object-mode default is 16 objects. fs.createReadStream() also defaults to 64 KiB unless you configure it differently. Older Node releases used different generic stream defaults, so do not design code around an exact default unless you are tying that decision to a specific Node version.
There is one text-specific detail to know. After readable.setEncoding() in non-object mode, Node compares the buffered string length against highWaterMark in characters instead of bytes. If your limit is byte-based, keep the stream as Buffers and decode at the place that owns text parsing.
highWaterMark is not a hard memory cap. A stream can hold a chunk larger than highWaterMark. A caller can keep writing after write() returns false. A Transform can expand one input chunk into much larger output. User code, native buffers, kernel buffers, and pending async work can all add memory outside the JavaScript stream queue. Stream memory stays under control only when every stage follows the stream contract.
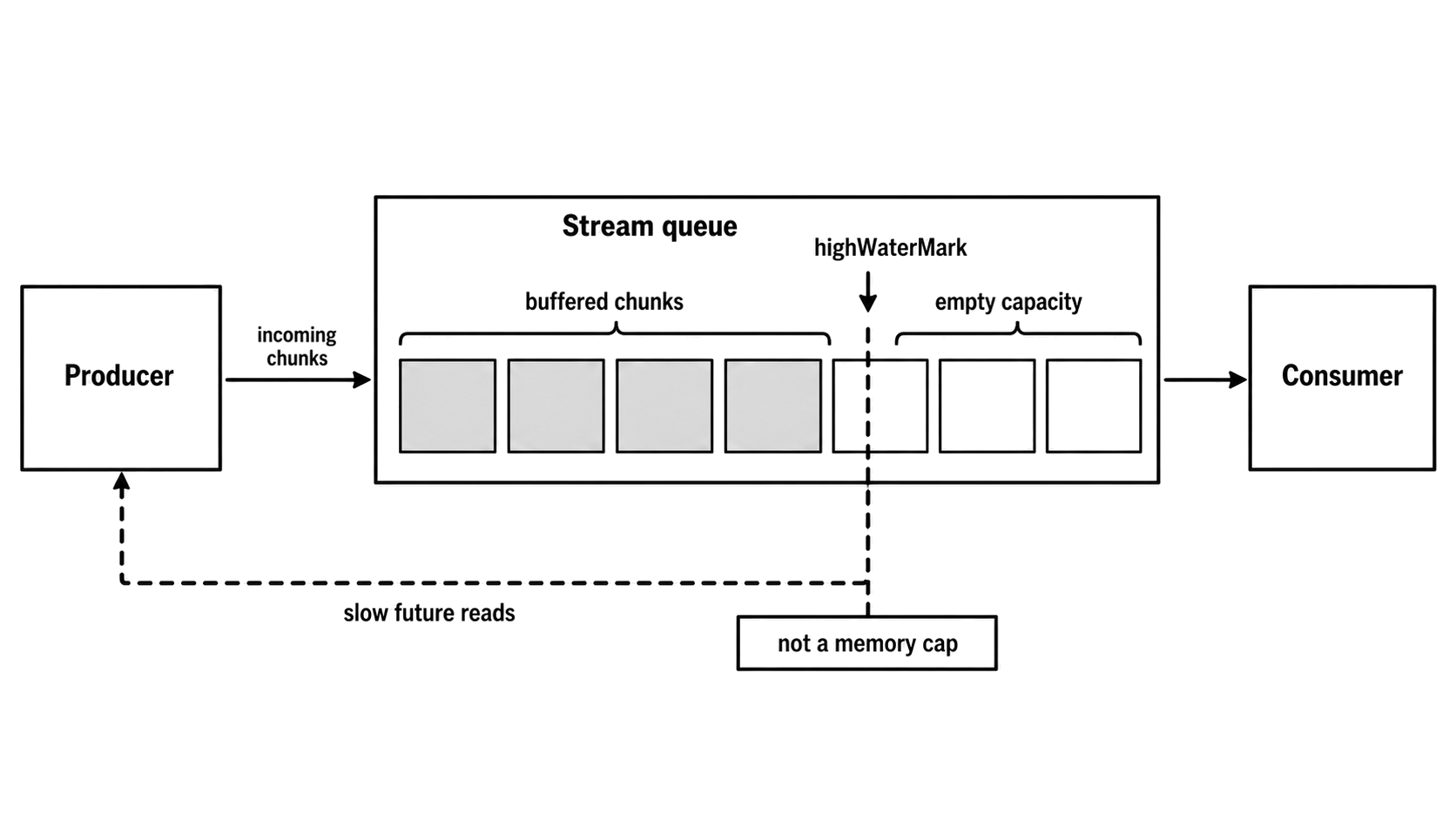
Figure 3.1 - A stream queue accepts chunks until its configured threshold tells upstream code to slow future reads. The threshold shapes demand; it is not a total process memory cap.
The Problem with Whole-Buffer Processing
A service that accepts uploaded files has to read bytes, maybe transform them, and send the result somewhere else. The most direct version reads the entire file, transforms the resulting Buffer, and writes the output -
import { readFile, writeFile } from "node:fs/promises";
function transform(buffer) {
return buffer;
}
const data = await readFile("input.mp4");
const processed = transform(data);
await writeFile("output.mp4", processed);The example uses local file paths, but an HTTP upload can end up with the same shape when the server collects the full request body before processing it.
For small files, that shape is often fine. For a 2 GB video, the process needs memory for the whole input plus whatever the transform allocates. Ten concurrent uploads multiply that peak. The failure might be an out-of-memory crash, a container kill, slower garbage collection, or high resident memory that remains visible after the request finishes.
This shape also forces the operation into three full phases: read everything, process everything, write everything. Node can still run other async work while readFile() waits on I/O, but this specific operation cannot transform the first byte until the full input has arrived. It also cannot write the transformed beginning until the transformation has finished.
Chunked processing changes that timeline. The first chunk can enter the transform while later bytes are still being read. Earlier output can be written while later input is still arriving.
Why Chunking Helps
Chunking means the program works on bounded pieces instead of one full input value. A file stream commonly reads around 64 KiB chunks by default in current Node, while an application pipeline may choose different thresholds. The exact chunking still depends on the stream implementation, its options, and the underlying resource.
The memory benefit is conditional, but real. The working set is no longer automatically tied to the total input size. It is shaped by stream queues, transform state, user allocations, native buffers, kernel buffers, and concurrency. When every stage respects backpressure, a 10 GB file does not require a 10 GB Buffer in JavaScript.
That change brings responsibilities too. Code has to decide when to read the next chunk, when to stop accepting chunks, how to report errors, how to release resources, and how to signal the end of data. Streams package those decisions into a contract used by file I/O, HTTP bodies, TCP sockets, compression, crypto, and userland pipelines.
Push and Pull Models
Streaming systems usually organize flow control around two models: push and pull. The difference is who starts the next transfer, which also decides where pressure can be expressed.
In a push model, the producer delivers chunks when it has them. The consumer registers callbacks or listeners and reacts when the producer emits data, so the producer's schedule drives the flow.
In a pull model, the consumer requests the next chunk when it is ready. The producer responds to explicit demand. JavaScript iterators and async iterators use this shape.
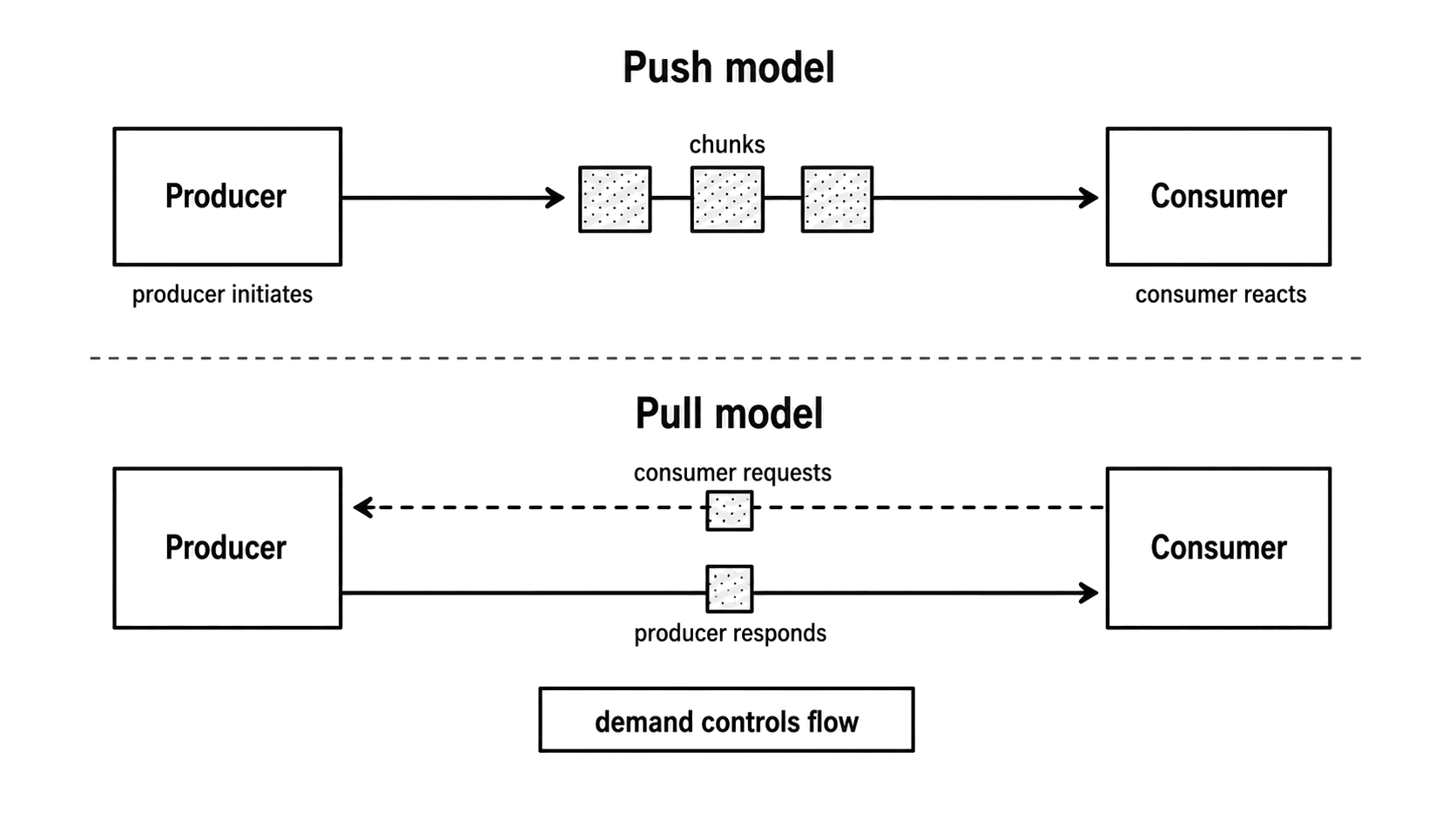
Figure 3.2 - Push delivery starts with the producer. Pull delivery starts with consumer demand, which gives pressure a natural place to appear.
Streams combine both models. A Readable can push through data events, but it can also sit in paused mode and let a consumer call read(). Writable streams expose pressure through write() and drain. Async iteration gives Readables a pull-oriented way to consume chunks. It is easier to understand those forms separately before looking at how Node combines them.
Push Delivery
The push model is event delivery. The basic primitive is EventEmitter, which calls registered listeners when an event is emitted. Streams inherit from this behavior, so a Readable in flowing mode can emit data, end, error, and close.
This small EventEmitter source shows the mechanics without trying to behave like a production stream.Readable. It intentionally leaves out errors, cancellation, lifecycle cleanup, and backpressure -
import { EventEmitter } from "node:events";
const source = new EventEmitter();
let index = 0;
function pushNext() {
if (index === 5) return source.emit("end");
source.emit("data", ++index);
setImmediate(pushNext);
}Using that source looks like this -
source.on("data", (chunk) => {
console.log("Received:", chunk);
});
source.on("end", () => {
console.log("Stream ended");
});
pushNext();The producer owns delivery timing, and the consumer reacts. The first call to pushNext() emits synchronously. Later chunks run through setImmediate(), so the source yields between chunks instead of emitting the whole sequence in one call stack.
EventEmitter.emit() calls listeners synchronously and ignores their return values. If a listener does CPU work, the producer is blocked during that call.
The risk changes when the listener starts async work and returns before that work finishes. The producer can keep emitting chunks while disk writes, network requests, or database calls from earlier chunks are still in flight. Those pending operations become a queue, even if the code never names it.
Backpressure is what naive push code is missing. The consumer needs a way to say "stop sending for now", and the producer has to respect that signal. Without it, memory growth moves into arrays, promise lists, socket buffers, native queues, or whatever else holds pending work.
Pull Demand
The pull model makes demand explicit. The consumer asks for the next value, and the producer does not hand over another value until that request happens.
JavaScript's Iterator protocol is the synchronous version of that contract. An iterator is an object with a next() method. Each call returns { value, done }, where done marks the end of the sequence -
function pullSource(data) {
let index = 0;
return {
next() {
if (index === data.length) return { done: true };
return { value: data[index++], done: false };
},
[Symbol.iterator]() { return this; },
};
}Using that iterator -
const source = pullSource([1, 2, 3, 4, 5]);
let result = source.next();
while (!result.done) {
console.log("Pulled:", result.value);
result = source.next();
}Here the consumer owns delivery timing. No callback fires just because data exists. The producer returns a value only when next() is called.
Generators and Iterable Protocol
Generator functions keep the same protocol while removing most of the setup code. A generator function uses function* and yield. Calling the function returns an iterator object -
function* pullSource(data) {
for (const chunk of data) {
yield chunk;
}
}The normal for...of loop keeps asking for values until the sequence ends -
for (const chunk of pullSource([1, 2, 3, 4, 5])) {
console.log("Pulled:", chunk);
}The loop calls next() until the iterator returns done: true. This is still a synchronous sequence. Arrays, Maps, Sets, strings, and generator results all participate because they implement the Iterable protocol through Symbol.iterator.
Async Iterators and for await...of
Real I/O usually cannot return the next chunk synchronously. Files, sockets, HTTP responses, and database cursors may need to wait for more data. Async iterators keep the same pull contract, but next() returns a Promise.
import { setImmediate as delayImmediate } from "node:timers/promises";
async function* asyncPullSource(data) {
for (const chunk of data) {
await delayImmediate();
yield chunk;
}
}The consumer uses for await...of -
for await (const chunk of asyncPullSource([1, 2, 3])) {
console.log("Pulled:", chunk);
}The loop waits for each next() Promise before running the body. Async iteration was standardized in ES2018, and Readable streams implement it. The syntax hides the Promise handling while keeping the same sequential pull behavior.
Pull-based backpressure works naturally only when the source is truly demand-driven. If the producer creates data only after next() is called, a slow consumer slows the producer.
If the underlying source is external, such as a WebSocket, message queue, or native callback source, an async-iterator wrapper still needs a bounded queue, a drop policy, or a real upstream pressure channel. A consumer can call next() before data arrives and wait for the Promise, but that does not make an externally driven producer demand-controlled.
Pull also has limited fan-out. One iterator advances one sequence. Once a consumer pulls a value, that value is consumed. Sending the same chunks to multiple consumers needs a separate tee or pub/sub layer with its own buffering rules.
The Hybrid Stream Model
Node streams are hybrid APIs. They extend EventEmitter, and a Readable can push chunks through data events in flowing mode. The same Readable also has paused mode, where consumers call read() or wait for readable before pulling from the internal buffer. Writable streams expose their own pressure through write() returning false and a later drain event.
Async iteration adds another way to consume the same stream state machine -
for await (const chunk of readable) {
await processChunk(chunk);
}By default, breaking out of for await...of over a Readable destroys the stream. That is often the right ownership rule for files and responses: early exit means the loop is done with the resource. When code needs to inspect a few chunks without destroying the stream, Node exposes readable.iterator({ destroyOnReturn: false }), but that should be an explicit choice.
Pick one consumption style per Readable: data, readable with read(), pipe() or pipeline(), or async iteration. Node's stream docs warn that mixing these styles on one Readable can produce unintuitive behavior because each style changes mode, buffering, and lifetime ownership.
How the Stream API Evolved
Streams have existed since early Node releases, but the first versions were strongly event-oriented. Older streams exposed pause(), but in Node v0.8 that signal was advisory. Some sources could still emit data after pause() while lower layers caught up.
Node v0.10 introduced Streams2, which formalized the modern Readable contract. Readables gained the paused and flowing modes used today. In paused mode, the consumer pulls with read(). In flowing mode, the stream emits data events.
A consumer with no pipe destinations can call pause() to stop automatic data delivery. In a piped flow, pressure is normally propagated by the Writable side: write() returns false, the pipe chain waits for drain, and the source stops being asked for more data while queues drain. Manual pause() is not the main pressure channel for pipe() or pipeline().
Later releases added higher-level coordination around that contract. Node v10.0 added callback-based stream.pipeline() and stream.finished(), and Readable async iterator support arrived in the Node 10 line before becoming non-experimental later. The Promise utilities used in modern examples live in node:stream/promises; that API was added in v15.0. Current Node keeps compatibility behavior because old stream patterns still exist in userland and in long-lived applications.
The Four Stream Types
Node defines four main stream roles, and the flow-control rules apply differently to each one.
Readable streams produce data. Examples include fs.createReadStream(), HTTP request bodies on the server, HTTP response bodies on the client, and process.stdin.
Writable streams consume data. Examples include fs.createWriteStream(), http.ServerResponse, and process.stdout.
Transform streams consume chunks on their writable side and emit derived chunks on their readable side. zlib.createGzip() and many crypto streams are Transform streams. The input and output can differ in size, so transform expansion belongs in any memory calculation.
Duplex streams are readable and writable, but the two directions are independent. net.Socket is the common example. Bytes written to the socket go out to the peer, while bytes read from the socket came from the peer. Writing to a socket does not directly create what you later read from that same socket.
These roles form pipelines. A Readable can feed a Transform, which can feed another Transform, which can feed a Writable. Data moves forward. Pressure moves backward. Memory stays controlled only while each stage honors the pressure signal and avoids unbounded side queues.
Pipeline Data Flow
A simple processing pipeline has three stages.
- A Readable reads chunks from a file.
- A Transform converts or compresses each chunk.
- A Writable writes the resulting chunks.
In application code, pipeline() is usually the right choice when the stream layer should coordinate backpressure, errors, and cleanup. This example assumes input.log exists -
import { createReadStream, createWriteStream } from "node:fs";
import { pipeline } from "node:stream/promises";
import { createGzip } from "node:zlib";
await pipeline(
createReadStream("input.log"),
createGzip(),
createWriteStream("input.log.gz"),
);The imported pipeline() is the promise-based API from node:stream/promises. It rejects when a stage fails and destroys connected streams according to the stream pipeline rules. That cleanup is useful for ordinary file and transform pipelines, but it can be user-visible when the destination is an HTTP response or socket. Connection-oriented code needs deliberate error handling.
When the Writable's queue reaches its threshold, write() returns false. The pipe or pipeline machinery stops requesting more data from upstream until the destination drains.
That does not mean every lower layer stops immediately. The Readable may already have buffered chunks, the file system or socket may have native buffers, and a Transform may already hold input or output. Backpressure coordinates future demand; it cannot remove work that has already entered a queue.
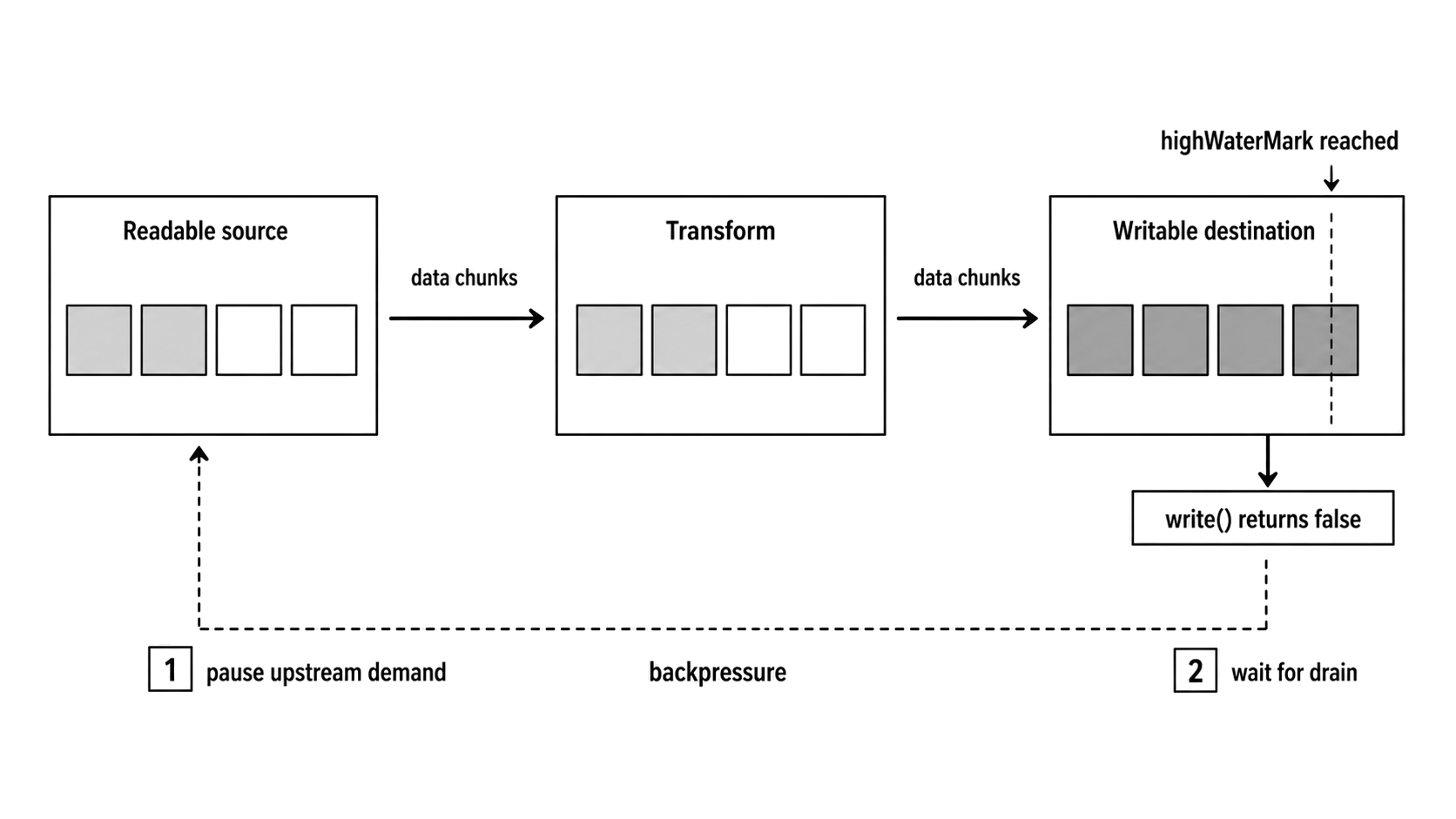
Figure 3.3 - Data moves from source to transform to destination, while backpressure travels in the opposite direction when a downstream queue reaches its threshold.
The useful property is that each stage can focus on one operation while pipeline() owns the normal flow-control and error path. Without pressure, a fast source can produce chunks faster than a slow destination can accept them. With pressure, the pipeline regulates around the slowest stage, subject to configured thresholds and any buffering outside the stream objects.
Streams do not make JavaScript CPU work parallel. A CPU-heavy transform still runs on the main JavaScript thread unless you move that work to another process, worker thread, or native path. Streams overlap I/O and incremental processing; they are not a replacement for CPU scheduling.
When to Use Streams
Streams fit large, unknown, or continuous data. Processing a multi-gigabyte log file usually calls for streaming. Handling an incoming HTTP request body of unknown size uses a stream because the body arrives incrementally. Implementing a raw TCP protocol uses streams because the connection is a byte flow over time.
Streams are less useful for small, known-size data. A 10 KB JSON configuration file in startup code is simpler as fs.readFile(), followed by JSON.parse(). In a server request path, prefer asynchronous file APIs or a cache; synchronous filesystem calls block the event loop for every other request handled by that process.
Plain file copies deserve a separate decision. If the job is "copy this file to that path" with no inspection or transformation, fs.copyFile() may be the better API. If the job is "read, parse, filter, compress, encrypt, proxy, or stream to a client", streams are usually the right abstraction.
Where Streams Appear
fs.createReadStream() and fs.createWriteStream() are the common file APIs when data must be processed or transferred incrementally.
HTTP request and response bodies are streams. A server can begin processing a request before the full body arrives, and it can begin sending a large response without first buffering the whole response in memory.
net.Socket is a Duplex stream. Proxy code can pipe bytes between sockets, but production protocols often need parser state between the readable and writable sides.
zlib and crypto expose Transform streams for compression, decompression, encryption, hashing, and related byte transformations. These stages can change chunk sizes, so output buffering needs to be part of the design.
ETL and log processing pipelines often combine byte streams with object-mode transforms. Readable.from() defaults to object mode unless you explicitly pass { objectMode: false }, so be deliberate when converting iterables into stream stages.
Readable streams are where these rules show up in code: mode changes, readableLength, readableHighWaterMark, _read(), push(), early destruction, and the point where a source is finally asked for more bytes.