Promise.all, allSettled, race & any
Promise combinators take multiple inputs and give you one promise back. That one promise follows a rule based on the combinator you choose.
Promise.all() waits for every input to fulfill. If one rejects, the whole thing rejects.
Promise.allSettled() waits for every input to finish, whether each one fulfilled or rejected.
Promise.race() follows whichever input settles first, success or failure.
Promise.any() waits for the first successful result. It only rejects when every input rejects.
Those differences look small when you read the API names, but they lead to very different behavior in real programs. The right combinator depends on what you actually want to know - did everything succeed, did everything finish, did anything finish first, or did at least one thing work?
Promise Combinators
Promise combinators coordinate promises that already exist. They do not make your work lazy. They do not limit how many operations start. They do not retry failed work. They do not cancel work that is no longer useful.
That part is easy to miss. When you write this -
const result = await Promise.all([
fetchUser(id),
fetchPosts(id),
fetchSettings(id)
]);the three function calls happen first. Each call creates and starts its work before Promise.all() receives the array. The combinator only watches those promises and decides how the single aggregate promise should settle.
That distinction becomes very important in Node.js because many promise-returning functions are connected to real resources below JavaScript - sockets, file descriptors, timers, stream buffers, database connections, child processes, and libuv requests. The aggregate promise can settle while those resources are still doing work.
So whenever you use a combinator, keep three questions separate -
- When does each operation start?
- Which result or failure should decide the aggregate promise?
- What should happen to work that is no longer needed?
Most production bugs around promise combinators come from mixing those questions together. The combinator decides the aggregate result. Your surrounding code owns start timing, cancellation, retry policy, and cleanup.
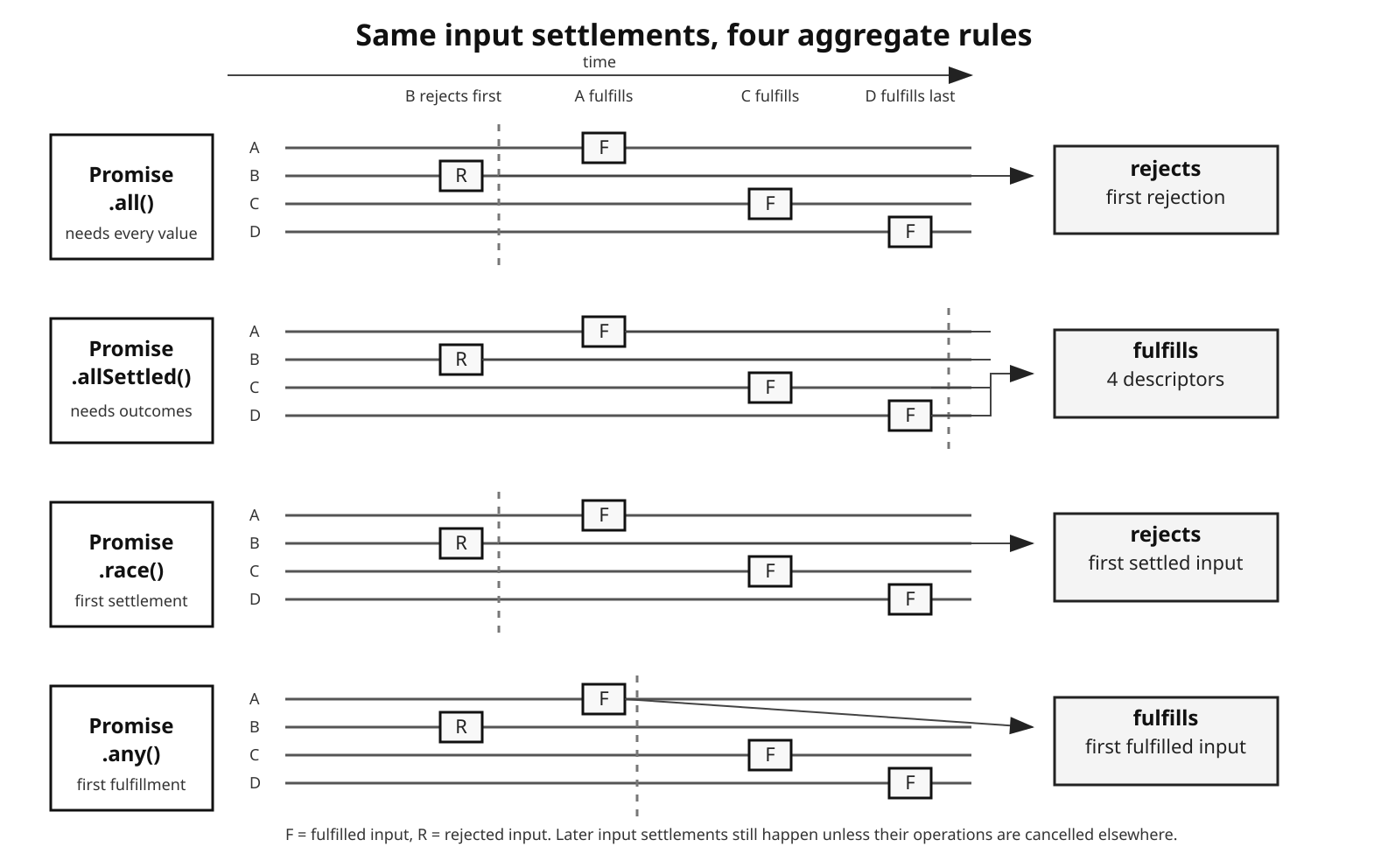
Figure 1 - The same inputs settle the aggregate promise at different times depending on the rule used by all(), allSettled(), race(), or any().
Promise.all()
Promise.all() is the one you use when every input is required.
It takes an iterable of values or promises and returns one promise. That returned promise fulfills with an array of values when every input fulfills. If any input rejects first, the returned promise rejects with that rejection reason.
A common example looks like this -
const [user, posts, settings] = await Promise.all([
fetchUser(id),
fetchPosts(id),
fetchSettings(id)
]);This is useful when the response needs all three pieces. If the user loads but the posts fail, the full operation should fail. If the posts load but the settings fail, same deal. Every result is required, so Promise.all() matches the policy.
The result array follows input order, not completion order. If fetchPosts(id) finishes first, its result still goes into the posts variable because that promise was at index 1 in the input array.
The function calls start before Promise.all() begins watching them. So if those functions start HTTP requests, the requests are already in flight by the time the combinator attaches handlers.
The fail-fast behavior comes from those attached handlers. As soon as the first input rejects, the aggregate promise rejects.
That does not stop the other inputs.
If fetchPosts(id) rejects after 50ms and fetchUser(id) fulfills after 200ms, the aggregate promise has already rejected by the time fetchUser(id) finishes. The later fulfillment cannot change the aggregate result, but the request still ran, its promise still settled, and the handler attached by Promise.all() still observed it.
That observation step is why later input rejections usually do not become unhandledRejection events. Promise.all() attaches rejection handlers to every input during the initial iteration. The later rejection is handled internally, even though the aggregate promise already rejected earlier.
The diagnostic downside is different. The caller only receives the first rejection reason. If three of five database calls fail, the caller sees one failure unless your code collects the other failures separately.
An empty iterable gives you an already-fulfilled promise -
const empty = Promise.all([]);The fulfillment value is []. The promise state is fulfilled immediately, but .then() callbacks and await continuations still run asynchronously after the current synchronous stack finishes. "Already fulfilled" describes the promise state. It does not mean observers run inline.
Plain values are allowed too -
const [count, response, label] = await Promise.all([
3,
fetch("https://api.example.com/user"),
"primary"
]);The plain values go through promise resolution, then land in the output array at their original positions. They do not make handlers run synchronously.
File fan-out is a common Node.js use case -
import { readFile } from "node:fs/promises";
const contents = await Promise.all(
files.map(file => readFile(file, "utf8"))
);This starts all reads before waiting for the aggregate result. If any read fails, Promise.all() rejects. The other reads keep running because Promise.all() does not own the filesystem requests. It only owns the aggregate promise.
Use Promise.all() when every result is required and one failure should fail the whole operation. Good examples include loading required configuration files, running independent queries that all feed one response, or fetching resources where partial output would be wrong.
The internal rule is reliable. The iterable is consumed synchronously. Each input gets an index. Each fulfillment stores its value at that index. The aggregate fulfills only after every input has fulfilled. Completion order changes timing, not result order.
Promise.allSettled()
Promise.allSettled() is for batches where you want the full outcome list.
It waits until every input has either fulfilled or rejected. Then it fulfills with an array of result objects. Rejections are recorded as data instead of rejecting the aggregate promise.
const results = await Promise.allSettled([
fetchUser(id),
fetchPosts(id),
fetchSettings(id)
]);Each result object has one of two shapes -
{ status: "fulfilled", value }
{ status: "rejected", reason }So consuming code usually branches on status -
for (const result of results) {
if (result.status === "fulfilled") {
handleData(result.value);
} else {
logError(result.reason);
}
}This is the right tool when one failed input should not hide the rest of the batch. Health checks, cache warming, cleanup jobs, notification fan-out, and indexing jobs often need this behavior. You want the complete list - what worked, what failed, and why.
There is one detail worth keeping clear. Input promise rejections become descriptors. Iterator failures still reject the combinator itself. If the input iterable throws while being read, or the iterator protocol fails, Promise.allSettled() rejects just like the other combinators.
The descriptor format also prevents a common mistake. The output is not an array of plain values. It is an array of outcome objects.
This extracts the successful values -
const fulfilled = results
.filter(result => result.status === "fulfilled")
.map(result => result.value);And this collects the failures -
const rejected = results.filter(result => result.status === "rejected");
if (rejected.length > 0) {
logger.warn(
`${rejected.length} operations failed`,
rejected.map(result => result.reason)
);
}allSettled() gives your code the failure policy. That only helps if your code actually reads the descriptors. Calling await Promise.allSettled(...) and ignoring the result means every failure was intentionally swallowed.
The word "settled" has a specific promise meaning. A promise starts pending. It settles once, either fulfilled or rejected. allSettled() waits until every input leaves the pending state, then records which way each one went.
Before Promise.allSettled() was added to JavaScript, people often wrote a small helper that turned fulfillment and rejection into data -
function reflect(promise) {
return promise.then(
value => ({ status: "fulfilled", value }),
reason => ({ status: "rejected", reason })
);
}Then they used it like this -
const results = await Promise.all(promises.map(reflect));That workaround expresses the same idea, but the built-in API is easier to read and harder to mess up during review.
Promise.race()
Promise.race() follows the first input that settles.
If the first settled input fulfills, the race fulfills. If the first settled input rejects, the race rejects. It does not wait to see whether a better result arrives later.
A timeout helper usually looks like this -
function timeout(ms) {
return new Promise((_, reject) => {
setTimeout(() => reject(new Error("Timeout")), ms);
});
}Then a timeout race looks like this -
const response = await Promise.race([
fetch("https://api.example.com/data"),
timeout(5000)
]);If the fetch fulfills first, response is the fetch result. If the timer rejects first, the await throws the timeout error.
The losing promise keeps running.
That is the main thing to remember with race(). A timeout race changes which promise the caller observes. It does not cancel the losing operation.
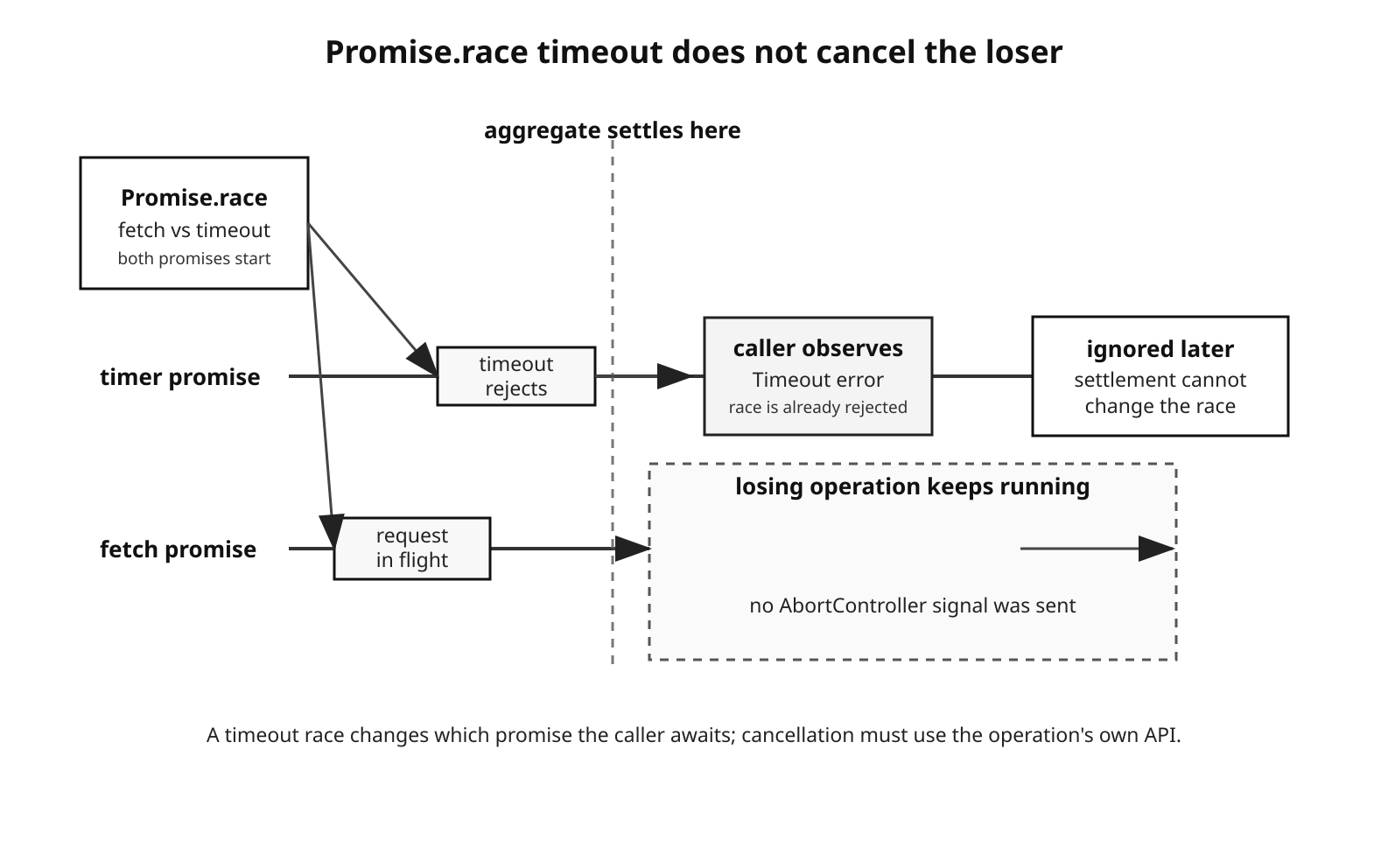
Figure 2 - A timeout can settle the race while the slower operation continues. Stop the loser through its own cancellation API if the work should end.
This is where resource bugs begin. If the timer wins, the HTTP request may still hold a socket, receive bytes, parse headers, and fulfill later. The returned response is ignored because the race already settled. For a small one-off script, that may be fine. In a busy server, repeating that pattern without cancellation can leave a lot of abandoned work running.
The empty case follows the same first-settlement rule -
const never = Promise.race([]);Promise.race([]) returns a promise that never settles. This can show up when an array is built dynamically. If filtering removes every candidate, await Promise.race(candidates) hangs forever unless you handle the empty case first.
race() is also a bad fit for fallback reads when a fast failure should not win. Suppose one mirror rejects in 5ms and another mirror fulfills in 100ms. Promise.race() rejects at 5ms. The successful mirror does not help.
For "try several sources and use the first success", use Promise.any().
Repeated races in loops need extra care. This code starts a new check whenever the timer wins -
async function pollWithRefresh(checkFn, intervalMs) {
while (true) {
const result = await Promise.race([
checkFn(),
timeout(intervalMs).catch(() => "timeout")
]);
if (result !== "timeout") return result;
}
}If checkFn() loses the race, it is not moved into the next iteration. It continues on its own. If it eventually fulfills, that result is discarded. If checkFn() regularly takes longer than intervalMs, the loop can build up many outstanding checks.
For polling, choose one of these shapes instead -
- make each check cancellable
- track outstanding checks deliberately
- run one check at a time, then sleep before the next attempt
An old race loser cannot settle a later race.
Promise.any()
Promise.any() is for "give me the first success."
It fulfills with the first input that fulfills. Rejections are ignored while another input could still fulfill. If every input rejects, the aggregate rejects with an AggregateError.
This makes it useful for redundant sources, mirrors, fallback endpoints, or anything where one working result is enough.
Native fetch() needs one extra wrapper before it behaves the way most people expect in these examples. HTTP error status codes do not reject the fetch promise. A 503 response still fulfills with response.ok === false. Network failures and aborts reject.
If HTTP 4xx and 5xx responses should count as failures, wrap the response check -
async function fetchOk(url, options) {
const response = await fetch(url, options);
if (!response.ok) {
const err = new Error(`HTTP ${response.status}`);
err.status = response.status;
err.response = response;
throw err;
}
return response;
}Now a CDN fallback reads the way it behaves -
const response = await Promise.any([
fetchOk("https://cdn-a.example.com/data"),
fetchOk("https://cdn-b.example.com/data"),
fetchOk("https://cdn-c.example.com/data")
]);The first HTTP-success response wins. A 503 or 429 becomes a rejection because fetchOk() throws. Without that wrapper, the first HTTP response would fulfill the fetch promise even if the server returned an error status.
If all inputs reject, inspect err.errors -
try {
await Promise.any(mirrors.map(url => fetchOk(url)));
} catch (err) {
console.log(err instanceof AggregateError);
console.log(err.errors.length);
console.log(err.errors.map(reason => String(reason)));
}AggregateError.errors contains the rejection reasons. Those reasons are not guaranteed to be Error objects. JavaScript allows code to reject with strings, numbers, objects, or errors. Real code should reject with Error instances, but diagnostic code should not assume every reason has .message.
The AggregateError object itself is not iterable. Use the .errors array.
In Node v24's V8, the rejection created by Promise.any() uses the message "All promises were rejected". If you create your own AggregateError, pass a message yourself when you want one -
throw new AggregateError(
[new Error("CDN-A down"), new Error("CDN-B timeout")],
"All CDNs failed"
);Like the other combinators, Promise.any() does not cancel losing work. Once one request succeeds, the other requests keep running unless your code cancels them.
Here is the quick comparison -
| Combinator | Fulfills when | Rejects when | Stops waiting early | Empty input |
|---|---|---|---|---|
Promise.all() | All inputs fulfill | First input rejects, or iterable fails | Yes, on first rejection | Already fulfilled with [] |
Promise.allSettled() | All inputs settle | Iterable or protocol fails | No, for input settlement | Already fulfilled with [] |
Promise.race() | First settlement is fulfillment | First settlement is rejection, or iterable fails | Yes, on first settlement | Pending forever |
Promise.any() | First input fulfills | All inputs reject, or iterable fails | Yes, on first fulfillment | Rejected with AggregateError |
Concurrency Limiting
Promise combinators aggregate promises. They do not control how many operations your code starts.
This starts one request per URL -
const results = await Promise.all(
urls.map(url => fetchOk(url))
);If urls has 500 entries, your code starts 500 fetches. The actual socket count depends on the HTTP client, target origins, dispatcher configuration, protocol, pooling, and operating-system limits. But at the JavaScript level, the fan-out is still 500.
When the number of operations can get large, you need a start policy. A concurrency limiter starts only a fixed number of operations at a time and leaves the rest waiting.
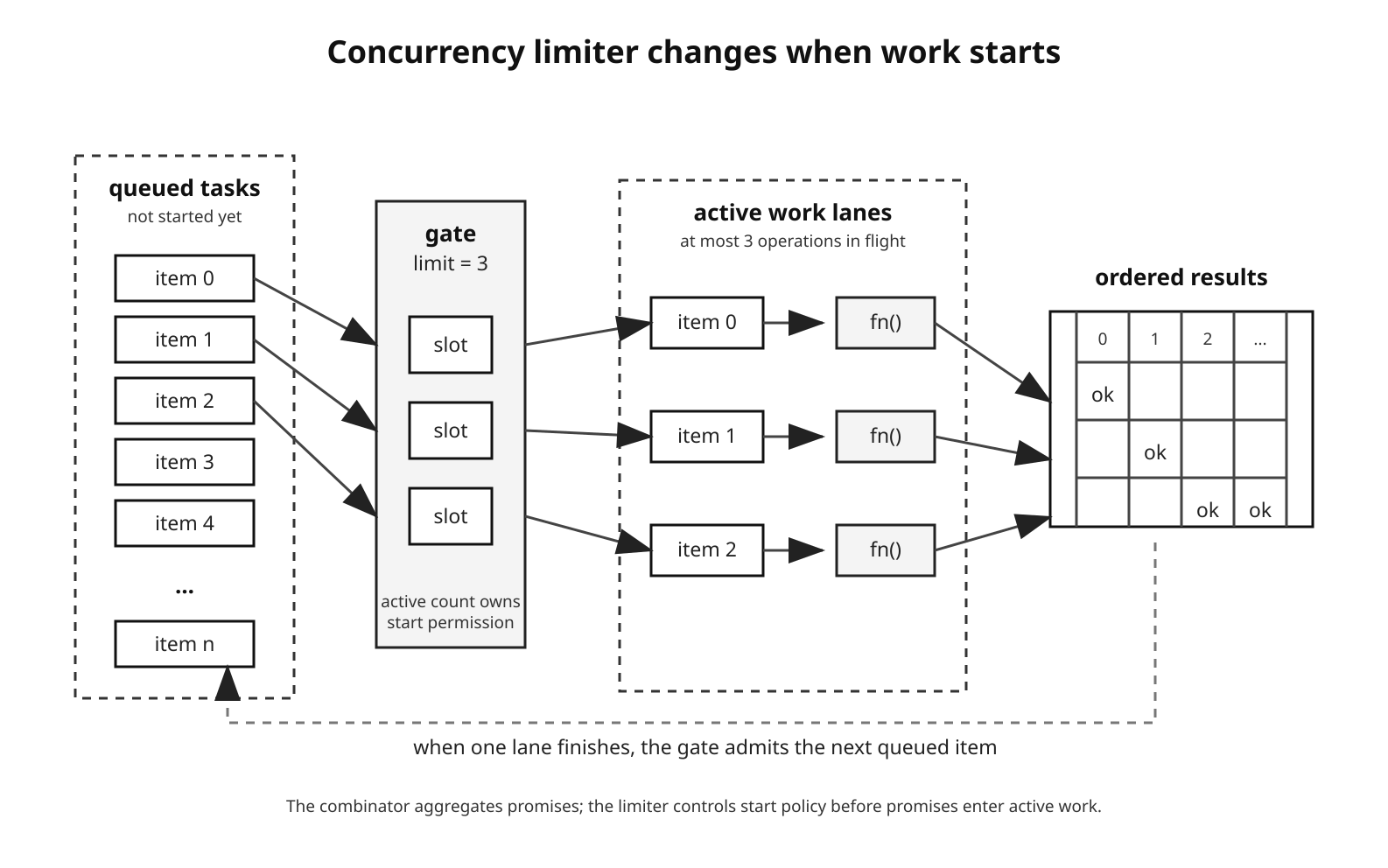
Figure 3 - A concurrency limiter changes when work starts. Only a bounded number of operations are active at once.
A simple pool-based mapper looks like this -
async function pMap(items, fn, concurrency) {
if (!Number.isInteger(concurrency) || concurrency < 1) {
throw new RangeError("concurrency must be a positive integer");
}
const results = new Array(items.length);
let nextIndex = 0;
async function worker() {
while (nextIndex < items.length) {
const index = nextIndex++;
results[index] = await fn(items[index], index);
}
}
const workers = Array.from(
{ length: Math.min(concurrency, items.length) },
worker
);
await Promise.all(workers);
return results;
}Each worker takes the next index, runs the function, stores the result, then takes another index. The nextIndex++ step is safe here because JavaScript runs one synchronous section at a time on this event loop. Another worker can resume only after the current worker reaches an await or returns to the runtime.
The caller still receives results in input order -
const responses = await pMap(
urls,
url => fetchOk(url),
10
);At most ten fetches are active. The result array preserves input order because each worker writes to its captured index.
If fn() rejects, the internal Promise.all(workers) rejects. Work that already started continues. Later errors may be hidden behind the first rejection. If the batch needs complete failure reporting, wrap each item with an allSettled()-style result object inside fn().
The limit also changes runtime shape. For mostly similar latencies, total time is roughly the number of waves multiplied by average latency. Real batches depend on slow items too. A slow item holds its worker slot longer, so the next queued item waits longer to start.
A reusable limiter exposes the same idea to multiple call sites -
function pLimit(concurrency) {
if (!Number.isInteger(concurrency) || concurrency < 1) {
throw new RangeError("concurrency must be a positive integer");
}
let active = 0;
const queue = [];
function runNext() {
if (active >= concurrency || queue.length === 0) return;
active++;
queue.shift()();
}
return function limit(fn) {
return new Promise((resolve, reject) => {
queue.push(() => {
Promise.resolve()
.then(fn)
.then(resolve, reject)
.finally(() => {
active--;
runNext();
});
});
runNext();
});
};
}The Promise.resolve().then(fn) line keeps all function outcomes on one path. It handles promise-returning functions, plain return values, and synchronous throws. The finally() block releases the slot when fn() succeeds or fails.
A version that calls fn().then(...) directly breaks when fn() returns a plain value. It can also leave active stuck when fn() throws before returning.
Use a pool when you have one fixed collection -
const bodies = await pMap(urls, fetchJsonOk, 20);Use a limiter when many parts of the app share the same resource budget -
const dbLimit = pLimit(20);
const user = await dbLimit(() => loadUser(id));This is a small counting limiter in JavaScript form. active counts occupied slots. queue holds waiting work. finally() releases a slot. There are no locks here because the shared counter is changed only during synchronous JavaScript execution. The operation behind fn may still use sockets, the kernel, or libuv's thread pool.
In production, you will usually use packages such as p-limit and p-map instead of local helpers. They add queue introspection, abort support, async-iterable support, skip controls, and tested edge-case behavior. Check the package version before assuming a specific option exists.
The right limit usually comes from outside the combinator -
- API rate limits return 429 responses or rate-limit headers.
- Database pools have a fixed connection count.
- File descriptor limits come from the shell, service manager, container, and host policy.
- Memory rises with every in-flight request, response buffer, parser state, closure, and retained request object.
Retry with Exponential Backoff
Retry belongs around a function, not around a promise value.
A promise represents one attempt that has already started. A function can start a fresh attempt each time retry calls it.
async function retry(fn, {
maxRetries = 3,
baseMs = 1000,
shouldRetry = () => true
} = {}) {
for (let attempt = 0; attempt <= maxRetries; attempt++) {
try {
return await fn();
} catch (err) {
if (attempt === maxRetries || !shouldRetry(err)) throw err;
const backoff = baseMs * 2 ** attempt;
const delay = backoff * (0.5 + Math.random() * 0.5);
await new Promise(resolve => setTimeout(resolve, delay));
}
}
}The delay grows after each failed attempt. With baseMs = 1000, the retry delays land around 500-1000ms, then 1000-2000ms, then 2000-4000ms with the jitter formula shown above.
AWS calls this family "equal jitter" - part of the delay is retained and part is randomized. Full jitter randomizes from zero to the current backoff cap, which spreads retry timing even more under heavy contention.
The shouldRetry function keeps permanent failures out of the retry loop -
const data = await retry(
() => fetchJsonOk("https://api.example.com/data"),
{
maxRetries: 3,
baseMs: 500,
shouldRetry: err => err.status === 429 || err.status >= 500
}
);That predicate depends on the earlier HTTP wrapper. fetchJsonOk() turns HTTP status into thrown errors with a .status property -
async function fetchJsonOk(url, options) {
const response = await fetchOk(url, options);
return response.json();
}Retry transient failures - connection resets, temporary DNS failures, socket timeouts, 503 responses, and 429 responses where retrying is allowed. Respect Retry-After when the server sends it.
Do not automatically retry bad input, authorization failures, missing resources, or validation errors unless the application has a specific reason.
Mutating operations need extra care. If a POST request creates a resource and the response is lost, retrying the same POST may create a duplicate. Use idempotency keys, client-generated operation IDs, or restrict automatic retry to safe reads and explicitly idempotent writes.
Immediate retries can make an overloaded dependency worse. Backoff lowers the retry rate. Jitter keeps many clients from retrying at the same moment.
Timeout and Cancellation
The timeout examples earlier only changed what the caller observed. They did not stop the losing operation.
AbortController is the standard cancellation mechanism for web-compatible APIs in Node.js. You create a controller, pass its signal to operations that accept it, and call abort() when the operation should stop.
The operation must actually observe the signal. A promise combinator cannot force that.
For fetch(), deadline cancellation can stay compact -
async function fetchWithTimeout(url, ms, options = {}) {
const signal = options.signal
? AbortSignal.any([options.signal, AbortSignal.timeout(ms)])
: AbortSignal.timeout(ms);
return fetchOk(url, { ...options, signal });
}AbortSignal.timeout(ms) creates a signal that aborts after ms. In Node, a timeout signal used with fetch() rejects with a TimeoutError DOMException. A manual AbortController.abort() usually produces an AbortError unless you pass a custom reason.
Below JavaScript, each API decides what abort means. For fetch(), aborting rejects the promise and aborts the request or body work. Transport cleanup, connection reuse, and protocol behavior are implementation details. Do not depend on "abort always closes this TCP connection" as a portable rule.
node:timers/promises accepts a signal directly -
import { setTimeout as sleep } from "node:timers/promises";
await sleep(5000, null, { signal });If the signal aborts first, the returned promise rejects with AbortError. The promisified timer API has accepted AbortSignal since Node 15.
Custom async utilities should follow the same shape -
function delay(ms, { signal } = {}) {
return new Promise((resolve, reject) => {
if (signal?.aborted) return reject(signal.reason);
const timer = setTimeout(done, ms);
function done() {
signal?.removeEventListener("abort", onAbort);
resolve();
}
function onAbort() {
clearTimeout(timer);
reject(signal.reason ?? new DOMException("Aborted", "AbortError"));
}
signal?.addEventListener("abort", onAbort, { once: true });
});
}The listener uses { once: true }, and the success path removes it. Without that cleanup, abort listeners can keep closures alive longer than needed.
A single signal can be passed through several operations -
const controller = new AbortController();
await Promise.all([
fetchData({ signal: controller.signal }),
processRecords({ signal: controller.signal }),
delay(1000, { signal: controller.signal })
]);Calling controller.abort() requests cancellation for all three. Only operations that accept and honor the signal will stop. If processRecords() ignores the option, it keeps running.
AbortSignal.timeout() is available in Node v17.3+ and v16.14+. AbortSignal.any() is available in Node v20.3+ and v18.17+. In Node v24, both are available globally -
const combined = AbortSignal.any([
userController.signal,
AbortSignal.timeout(10_000)
]);The combined signal aborts when any input signal aborts. This composes cancellation signals. It does not compose promise values.
AbortSignal support has spread across Node's API surface. Useful examples include node:fs/promises read/write methods, callback node:fs read/write methods that accept options, node:stream/promises.pipeline, events.once(), events.on(), child_process.exec(), child_process.spawn(), fetch(), and node:timers/promises.
Filesystem aborts are best effort around Node's internal buffering. An abort may stop more work from being scheduled, but it may not undo bytes already read or written.
Composing Patterns
Real code usually layers these tools.
A good shape is often - limit the batch outside, retry each item, give each attempt a deadline, then aggregate the batch result.
const results = await pMap(urls, url => {
return retry(
() => fetchWithTimeout(url, 5000).then(r => r.json()),
{
maxRetries: 3,
baseMs: 500,
shouldRetry: err => err.status === 429 || err.status >= 500
}
);
}, 10);The outer pMap() starts at most ten URLs at a time. retry() controls the attempt policy for one URL. fetchWithTimeout() gives each attempt a cancellable deadline. The Promise.all() inside pMap() waits for the workers, not for every URL at once.
Partial health checks often combine race() and allSettled() -
const health = await Promise.allSettled(
services.map(service =>
Promise.race([
checkService(service),
timeout(2000)
])
)
);This gives you every service outcome while limiting how long each individual wait can affect the batch. It still does not cancel checkService() after timeout. Use an abortable check function when the underlying operation supports cancellation.
CDN fallback needs success selection and loser cleanup -
async function firstJson(urls, timeoutMs) {
const deadline = AbortSignal.timeout(timeoutMs);
const controllers = urls.map(() => new AbortController());
const attempts = urls.map((url, index) => {
const signal = AbortSignal.any([deadline, controllers[index].signal]);
return fetchJsonOk(url, { signal }).then(data => ({ data, index }));
});
try {
const { data, index } = await Promise.any(attempts);
controllers.forEach((controller, i) => {
if (i !== index) controller.abort();
});
return data;
} catch (err) {
controllers.forEach(controller => controller.abort());
throw err;
}
}Each request gets its own controller, combined with the overall deadline. The winning request resolves after fetchJsonOk() has consumed the response body, so aborting the losers does not affect the returned body.
If every CDN fails, Promise.any() rejects with an AggregateError that contains the individual rejection reasons. If the deadline fires first, requests that honor the signal reject through abort.
Each piece has a focused job. Promise.any() chooses the first success. AbortController requests cancellation. fetchJsonOk() decides which HTTP responses count as failures. Keeping those jobs separate makes the code much easier to reason about.
How V8 Implements the Combinators
The behavior you observe comes from the ECMAScript algorithms. V8 implements the main combinator paths as Torque builtins that follow those algorithms while adding engine-specific fast paths.
The relevant source lives in files such as src/builtins/promise-all.tq, promise-race.tq, and promise-any.tq. Torque is V8's internal language for defining builtins. It is not ordinary JavaScript, and the exact implementation can change across V8 versions.
For Promise.all(), the engine keeps a remaining-elements count, a result array, and per-element reactions that remember their input index. When an input fulfills, its reaction stores the value at the captured index and reduces the remaining count. When the count reaches zero, the aggregate resolves with the result array.
The rejection path uses the aggregate promise's reject capability. The first input rejection settles the aggregate. Later fulfillment or rejection handlers may still run, but attempts to settle the already-rejected aggregate are ignored by the promise machinery.
Promise.allSettled() uses a similar shape. The difference is that both fulfillment and rejection reactions store descriptors, then reduce the remaining count. Input rejection becomes data. Iterator or protocol failure still rejects the aggregate.
Promise.race() needs less bookkeeping. It does not need a result array, error array, or remaining count. It still resolves each input through the promise machinery and attaches reactions. Native-promise fast paths can avoid some general .then() overhead, but slow paths still exist for thenables, subclassing and species behavior, hooks, debugging, and other observable cases.
Promise.any() tracks rejection reasons by input index and keeps a remaining count. Fulfillment resolves the aggregate. Each rejection stores its reason. If every input rejects, V8 creates an AggregateError from those reasons and rejects the aggregate.
For ordinary batches of tens of promises, this bookkeeping is usually not the performance problem. Huge batches are different. A Promise.all() over 100,000 already-started operations has to iterate the input and attach handlers to all of them before the aggregate can be useful. That up-front observation work can become visible.
Production Edge Cases
The combinator settles one aggregate promise. Your code still owns start timing, cancellation, retry policy, diagnostics, and fan-out size.
Lost diagnostics in Promise.all(). The aggregate rejects with the first rejection reason. Later rejection reasons are observed internally but not exposed through the aggregate. Use allSettled() when the caller needs the whole failure set.
Manual all-settled wrapping. Sometimes you want Promise.all() to fulfill with mixed values and errors -
const results = await Promise.all(
urls.map(url =>
fetchJsonOk(url).catch(error => ({ error }))
)
);That is a local policy choice. It turns failures into values, so the caller must inspect the array.
Sequential work by accident.
const a = await fetchA();
const b = await fetchB();
const c = await fetchC();fetchB() starts after fetchA() fulfills. fetchC() starts after fetchB() fulfills. If the work is independent, start the promises together -
const [a, b, c] = await Promise.all([
fetchA(),
fetchB(),
fetchC()
]);The function call starts the work. await waits for the result.
Ignored race losers. If a timeout wins a Promise.race(), the losing operation may still fulfill later. That later fulfillment is ignored. The resource cost can still count.
AggregateError.errors is the useful array. This does not work -
for (const err of aggregateError) {
console.log(err);
}AggregateError itself is not iterable. Use .errors -
for (const err of aggregateError.errors) {
console.log(err);
}Microtask ordering. Already-fulfilled inputs do not make combinator observers run inline. Promise.all([Promise.resolve(1)]) still delivers .then() handlers and await continuations asynchronously. Avoid teaching exact microtask counts. The count can change depending on native promise fast paths, thenables, and surrounding scheduling. The stable rule is simple - current stack first, promise observers later.
Sparse arrays. Array holes are treated as undefined values during iteration -
const result = await Promise.all([
Promise.resolve("a"),
,
Promise.resolve("c")
]);
// ["a", undefined, "c"]No warning is emitted. If a dynamically built promise array has holes, the combinator preserves them as undefined results.
allSettled() in loops. This is usually a bug when failures are ignored -
for (const batch of batches) {
await Promise.allSettled(batch.map(processItem));
}The loop processes every batch and drops every rejection descriptor. If failure should affect control flow, count, log, aggregate, or throw based on the descriptors before moving to the next batch.
The recurring rule is simple. Combinators decide aggregate settlement. Your code decides when work starts, how much work starts, when to cancel, when to retry, and how to inspect the result.