Node.js Microtasks: Promise Jobs, process.nextTick, and Timer Order
Promise syntax makes async code look almost linear, but the runtime still follows its own scheduling rules. A promise handler does not run at the exact line where you attach .then(), .catch(), or .finally(). It runs later, after the current JavaScript stack has finished.
Most of the time, promise handlers run before timers, I/O callbacks, and setImmediate() callbacks. That simple rule is useful, but it is not the whole story in Node. Node has more than one queue involved, and the active scheduling context can change the order.
At a CommonJS main-script checkpoint, Node drains process.nextTick() callbacks before V8 microtasks. ES module top-level code already runs through a different evaluation path, so the same tiny example can print in a different order. Code already running inside a microtask has another ordering rule again.
So instead of treating "microtask order" like one universal rule, this chapter keeps the context visible.
Microtask Order at a Glance
Here is the short version before we walk through the examples -
| Scheduling context | Node v24 order after the current stack |
|---|---|
| CommonJS main script | process.nextTick() callbacks, then V8 promise jobs and queueMicrotask() callbacks, then event-loop callbacks such as timers, most I/O, and setImmediate() |
| ES module top level | V8 promise jobs and queueMicrotask() callbacks already in the module evaluation drain, then process.nextTick() callbacks, then event-loop callbacks |
| Inside an existing microtask | V8 microtasks queued during the active drain, then process.nextTick() callbacks created during that drain, then later event-loop callbacks |
Keep this table nearby while reading the rest of the chapter. Most confusing promise-order examples become easier once you know which queue is currently active.
Promise Microtasks
A promise reaction is the work scheduled by .then(), .catch(), .finally(), or the continuation after await. When you chain promises, every link adds more reaction work to the same microtask system. Rejection handling uses that system too.
That is also why unhandled rejection reporting waits briefly. The runtime gives your code a chance to attach a rejection handler before it decides the promise was left unhandled.
The usual timer example comes from this queue difference. Promise.resolve().then() often runs before setTimeout(fn, 0) because the promise reaction is ready at the next microtask checkpoint. The timer callback goes through libuv's timer system. A zero millisecond delay means the timer can run on a later event-loop turn. It does not mean "run right now".
These two callbacks live in the same process, but they enter different scheduling systems. The .then() handler becomes a V8 microtask. The timer callback waits inside libuv. Node decides when each side gets drained as it moves between JavaScript execution and event-loop work.
Before we get into those checkpoints, we need the basic promise state model.
A promise starts as pending. It can settle once, either fulfilled or rejected. Once that happens, the state and result stay fixed for every observer that comes later.
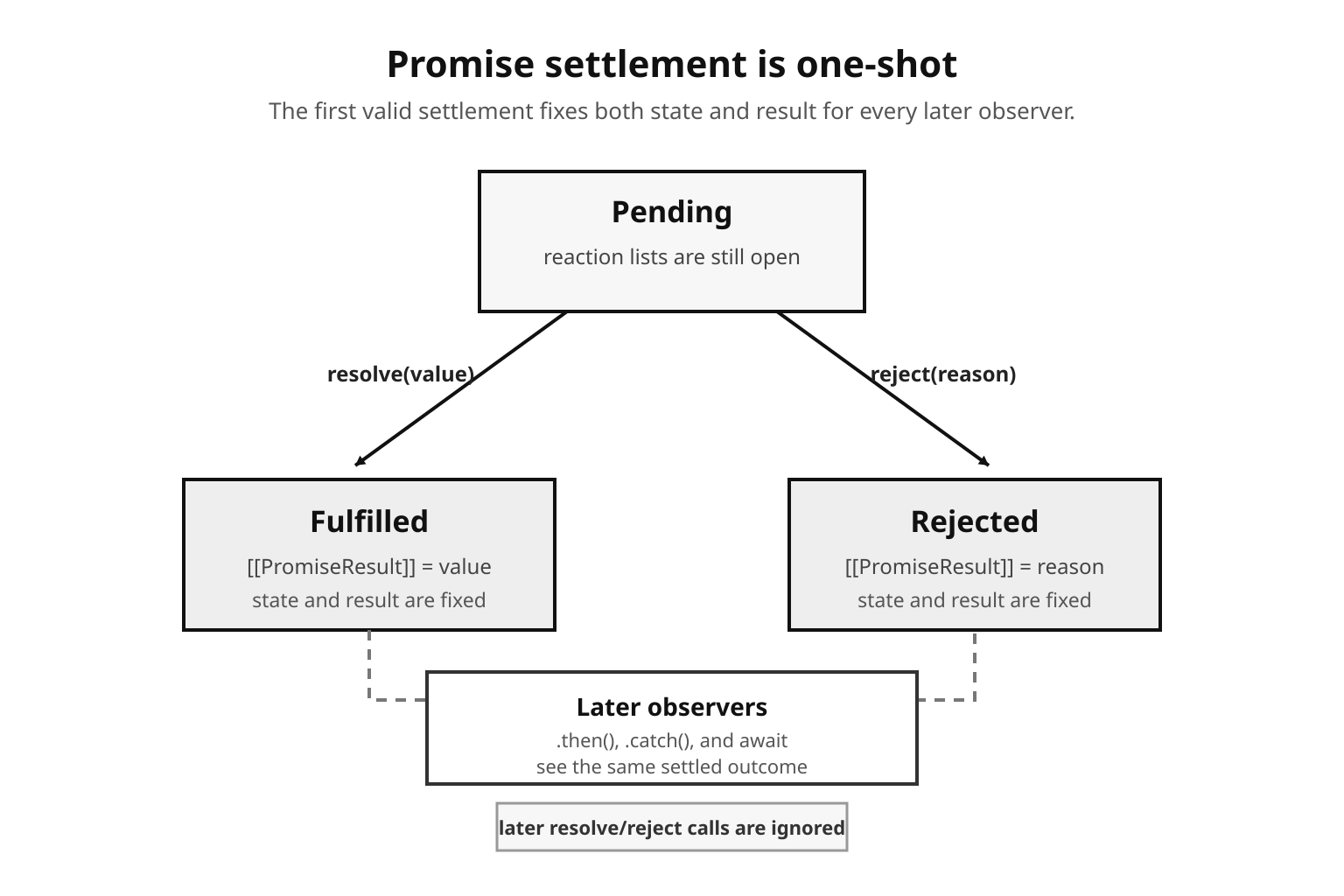
Figure 1 - A promise settles once. Pending becomes fulfilled or rejected, and that chosen state stays fixed for every later observer.
The ECMAScript model describes that state with internal slots. [[PromiseState]] is pending, fulfilled, or rejected. [[PromiseResult]] holds the fulfillment value or rejection reason. A pending promise also keeps lists of fulfillment and rejection reactions for handlers registered through .then(), .catch(), and .finally().
Engines can store those details however they want internally. The behavior your code can observe is simpler - handlers run once, and handlers attached to the same promise run in registration order.
JavaScript code cannot read those slots directly. console.log(promise) in Node may show <pending> or a fulfilled value through inspector formatting, but there is no normal property access for [[PromiseState]]. You observe a promise by attaching reactions. That keeps state changes and observation on the same scheduling path.
The constructor's resolve and reject functions are part of a promise capability. That capability connects three things - the promise object, the function that fulfills it, and the function that rejects it. Promise reaction jobs use those capabilities so each .then() link can settle the promise it returned.
That means a handler return value affects the next promise in the chain, not the promise that triggered the handler.
const p = new Promise((resolve, reject) => {
resolve(42);
resolve(99);
reject(new Error("too late"));
});
p.then(v => console.log(v)); // 42The first resolve(42) fulfills the promise. The later resolve(99) and reject() calls do nothing observable. The resolving functions share an already-resolved flag, so only the first settlement attempt can win.
That single-settlement rule removes one common callback-era bug. A callback can accidentally fire twice if an API author makes that mistake. A promise capability can be called twice too, but only the first call changes the promise.
The fulfillment value can be any JavaScript value - a primitive, an object, undefined, or another promise. Rejection can also use any value, although real code should reject with Error instances. A string rejection gives downstream code only a bare string. It has no name, no useful message, and no stack.
Promise resolution also protects against self-resolution. If code tries to resolve a promise with itself, the promise rejects with a TypeError. Without that guard, the promise would wait on its own settlement forever.
let resolve;
const p = new Promise(r => {
resolve = r;
});
resolve(p);
p.catch(e => console.log(e.name)); // TypeErrorYou mostly see this in hand-written adapters. Promise resolution is recursive by design, so the runtime needs a clear stop condition when a promise points back to itself.
The Executor Runs Inline
The function passed to new Promise() is called the executor. The constructor calls it immediately on the current JavaScript stack.
console.log("before");
const p = new Promise((resolve, reject) => {
console.log("executor");
resolve("done");
});
console.log("after");The output is before, executor, after.
Promise construction is synchronous. If the executor resolves immediately, the promise is already fulfilled by the time the constructor returns. The handler still runs later because .then() schedules a reaction job instead of calling the handler inline.
That separation is easy to miss at first. Creating the promise can validate inputs, capture state, start work, and even settle the promise before returning. Observing the result still happens later, on a clean stack, after the current JavaScript turn finishes.
The constructor creates the resolve and reject functions and passes them to the executor. After construction, outside code can attach reactions with .then(), .catch(), and .finally(). Outside code cannot settle the promise unless the executor leaks one of those functions.
Leaking the capability is possible -
let finish;
const p = new Promise(resolve => {
finish = resolve;
});
finish("done");That pattern is often called a deferred promise. It can be useful at integration points, such as waiting for a one-time event, bridging a callback API, or wiring a test harness.
Use it carefully. Once resolve or reject leaves the executor, any code holding that function can settle the operation. Keep those functions scoped as tightly as you can.
If the executor throws, the constructor turns that throw into a rejection -
const p = new Promise(() => {
throw new Error("executor exploded");
});
p.catch(e => console.log(e.message)); // "executor exploded"The constructor wraps the executor call. A synchronous throw becomes the rejection reason. The handler that observes that reason still runs later through the normal microtask path.
Promise.resolve(value) and Promise.reject(reason) create settled promises without writing the constructor form.
Promise.resolve(42) gives you a fulfilled promise. Promise.reject(new Error("no")) gives you a rejected promise. Tests, adapters, and small library branches use these helpers all the time.
Native promises also get an identity fast path -
const original = Promise.resolve(1);
const wrapped = Promise.resolve(original);
console.log(original === wrapped); // trueWhen the input is already a promise created by the same constructor, Promise.resolve() returns that same object. The engine does not need to wrap it.
Thenables follow a different path, and Promise subclasses can change the identity case. Promise.resolve() checks constructor identity, so a promise created by a different promise constructor may be wrapped in a new object using the requested constructor. Most application code never needs that detail, but Promise subclass authors do.
Resolving With a Promise
Resolving a promise with another promise does not fulfill the outer promise with the inner promise object. The outer promise follows the inner promise's eventual state.
const inner = new Promise(resolve => {
setTimeout(() => resolve("delayed"), 100);
});
const outer = new Promise(resolve => {
resolve(inner);
});
outer.then(v => console.log(v)); // "delayed" after 100msouter stays pending while inner is pending. When inner fulfills with "delayed", outer fulfills with "delayed". If inner rejects, outer rejects with the same reason.
The same resolution procedure works for thenables. A thenable is any object with a callable .then property. Promise resolution reads the .then property, checks whether it can be called, then schedules work that calls it with the outer promise's resolve and reject functions.
That protocol is what lets native promises, old promise libraries, and custom promise-like objects work together.
The .then property is read once. If a getter for .then throws, the promise rejects with that thrown error. If the getter returns a non-callable value, the object becomes the fulfillment value. If it returns a function, the promise algorithm keeps that function reference, and later changes to obj.then do not affect the scheduled work.
const thenable = {
then(onFulfill) {
onFulfill("from thenable");
}
};
Promise.resolve(thenable).then(v => console.log(v));The output is "from thenable". The object is treated as promise-like, and the outer promise follows the result produced by its .then() method.
Thenable handling adds scheduling work. A plain value can fulfill a promise immediately, while attached handlers still run later as reaction jobs. A thenable goes through PromiseResolveThenableJob, which calls the .then() method later from the microtask queue. When that thenable calls the supplied fulfillment function, the usual PromiseReactionJob work for handlers gets scheduled.
Most code does not need to care about that extra turn. Precise ordering tests can observe it.
The check is duck-typed. Object plus callable .then is enough. That makes interop possible, but it can also catch data objects by surprise. A database document, API response, or mock object with a callable then property gets treated as a thenable when passed to resolve().
If that method throws, the outer promise rejects. If it never calls either callback, the outer promise stays pending.
When that happens, the usual fix is to wrap the value inside another object, rename the property, or return the value from a handler that already runs after the assimilation step. This tends to show up in integration code, where external data crosses a promise boundary.
Thenables can also behave badly. The .then() method can call fulfillment twice, call rejection after fulfillment, throw after calling fulfillment, or call both callbacks from different turns. Promise resolution protects the outer promise with an already-resolved flag.
First call wins. Later calls return without changing the result. A throw after a successful callback is ignored because the outer promise has already been settled through that capability.
const messy = {
then(resolve, reject) {
resolve("ok");
reject(new Error("late"));
}
};
Promise.resolve(messy).then(v => console.log(v));The output is "ok". The rejection attempt comes after fulfillment and changes nothing.
This already-resolved flag is separate from [[PromiseState]]. It protects the resolving function during adoption, before the outer promise necessarily reaches its final state.
This adoption path is one reason promise code can look synchronous while still running later. A thenable may call resolve() inline from its .then() method, but the outer promise still schedules handlers through microtasks. Handler execution waits for the checkpoint.
Chaining
.then() accepts two optional handlers, onFulfilled and onRejected. Every call returns a new promise.
const result = Promise.resolve(5)
.then(v => v * 2)
.then(v => v + 1)
.then(v => console.log(v)); // 11Those three .then() calls create three promises. Each handler receives the value from the previous link. A normal return fulfills the next promise with that returned value. A throw rejects the next promise. Returning another promise makes the next promise follow that returned promise's state.
That is the real data flow in a chain. Each link controls the promise to its right. Each handler turns the previous result into the next result.
A missing return can quietly change the value that moves through the chain -
Promise.resolve("user")
.then(name => {
name.toUpperCase();
})
.then(v => console.log(v)); // undefinedThe first handler does call name.toUpperCase(), but it does not return the result. So the next promise fulfills with undefined. The runtime cannot know that this was accidental. Linters catch many of these, but the runtime behavior is silent.
Throws become rejections -
Promise.resolve("ok")
.then(v => {
throw new Error("oops");
})
.then(v => console.log("skipped"))
.catch(e => console.log(e.message)); // "oops"The second .then() has only a fulfillment handler, so the rejection passes through it. .catch(fn) is the same as .then(undefined, fn), which means it attaches a rejection handler to the promise produced by the previous link.
Where you place .catch() changes what it can handle. A .catch() at the end can handle failures from every earlier link. A .catch() in the middle can recover and send a normal value downstream.
Promise.reject(new Error("fail"))
.catch(e => "recovered")
.then(v => console.log(v)); // "recovered"The catch handler returns a string, so the promise it creates fulfills with that string. The following .then() receives it. If the catch handler threw instead, the chain would stay on the rejection path.
.finally(fn) runs for both fulfillment and rejection. It does not receive the value or reason. It passes the original value or reason through unless it throws or returns a rejected promise.
Promise.resolve(42)
.finally(() => console.log("cleanup"))
.then(v => console.log(v)); // "cleanup" then 42Use .finally() for cleanup that should happen after completion without changing the result - close a handle, clear a timer, release a lock, or decrement an in-flight counter.
The two-argument form of .then() has a narrower attachment point. In .then(onFulfilled, onRejected), the rejection handler handles rejection from the previous promise. It does not handle a throw from onFulfilled in the same call.
A chained .catch() handles the promise returned by .then(), so it catches throws from the fulfillment handler. End-of-chain .catch() is usually easier to read.
Empty .then() calls create pass-through promises. promise.then() follows the original promise and adds allocation. These often appear after refactors. Delete them when they have no handler.
One chaining rule is very helpful during debugging. Handlers attach to the promise on their left.
In a.then(f).catch(g), g handles rejections from a and throws from f, because it attaches to the promise returned by then.
In a.then(f, g), g handles only rejection from a. The promise returned from that call receives whatever f or g produces.
Same API. Different control flow.
Multiple handlers on the same promise are not a chain. They all observe the same settlement value, and each .then() call returns its own next promise.
const p = Promise.resolve(10);
p.then(v => console.log(v + 1));
p.then(v => console.log(v + 2));
p.then(v => console.log(v + 3));The output is 11, 12, 13. All three reactions attach to p, so they run in registration order when p settles. The return value from the first handler only feeds the promise returned by the first .then() call. It has no effect on the second or third handler.
Now compare that with a real chain -
Promise.resolve(10)
.then(v => v + 1)
.then(v => v + 2)
.then(v => console.log(v + 3));The output is 16. Each handler attaches to the promise returned by the previous .then(), so the value moves link by link.
That difference explains many confusing refactors. Splitting a chain into separate .then() calls on the original promise changes data flow, even though the method names still look similar.
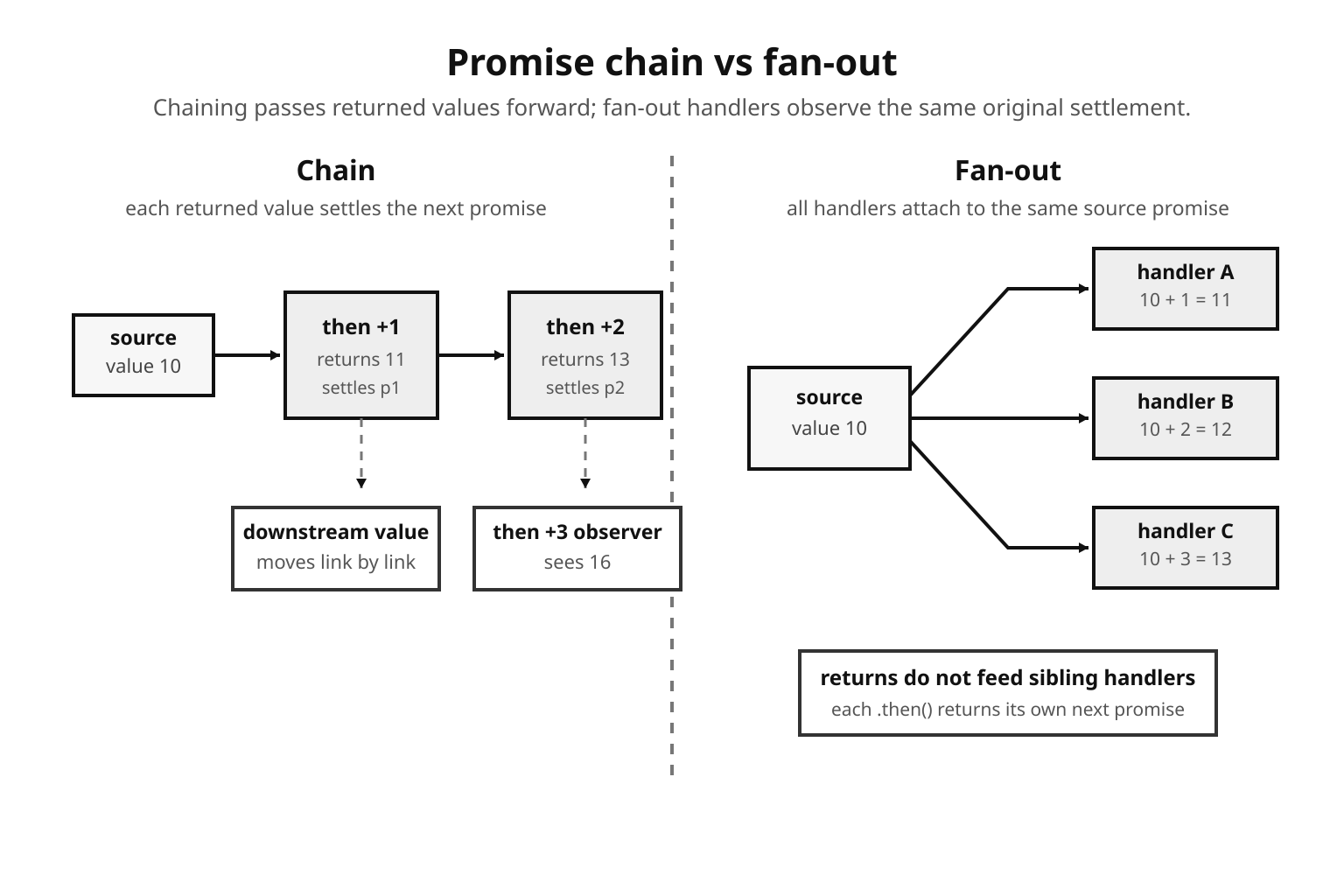
Figure 2 - A chain passes each returned value to the next link. Multiple handlers attached to the same promise each receive the same original settlement.
The same rule applies to errors. Three .catch() calls attached to one rejected promise all see the same rejection. Three catch handlers chained together form a recovery sequence, where each handler's return or throw decides what happens next.
Handler placement is the control flow.
How Promise Handlers Run
A handler never runs from inside .then().
If the promise is pending, .then() stores fulfillment and rejection reactions on that promise. If the promise is already settled, .then() creates the matching reaction job right away. In both cases, the handler itself runs later from V8's microtask queue.
V8's microtask queue sits beside the event-loop machinery. It holds promise reactions and queueMicrotask() callbacks. Libuv timers, I/O callbacks, and setImmediate() callbacks live outside it. process.nextTick() is separate again. It is a Node-managed queue, not V8's microtask queue.
The ECMAScript job for a promise reaction is called PromiseReactionJob. Its visible job is simple - call the right handler with the settled value, inspect what the handler returned or threw, then settle the promise returned by the .then() call.
A reaction carries the handler, the reaction type, and the promise capability for the next promise in the chain.
Missing handlers have defined pass-through behavior. For fulfilled promises, a missing fulfillment handler passes the same value onward. For rejected promises, a missing rejection handler passes the same reason onward as a rejection. Engines do not have to allocate real user-visible functions for those paths. The downstream behavior is what your code sees.
The specification models pending promises as holding fulfillment and rejection reactions. Engines can store those reactions however they choose, but the stable behavior is registration order and one-shot dispatch. Once a promise settles, later .then() calls still work by enqueueing new reaction jobs against the already-settled result.
When V8 begins a microtask checkpoint, it keeps running microtasks until the queue is empty. Promise jobs created during that drain join the same queue. queueMicrotask() jobs created during that drain do the same. Timers, I/O callbacks, and native callbacks wait outside the active microtask drain.
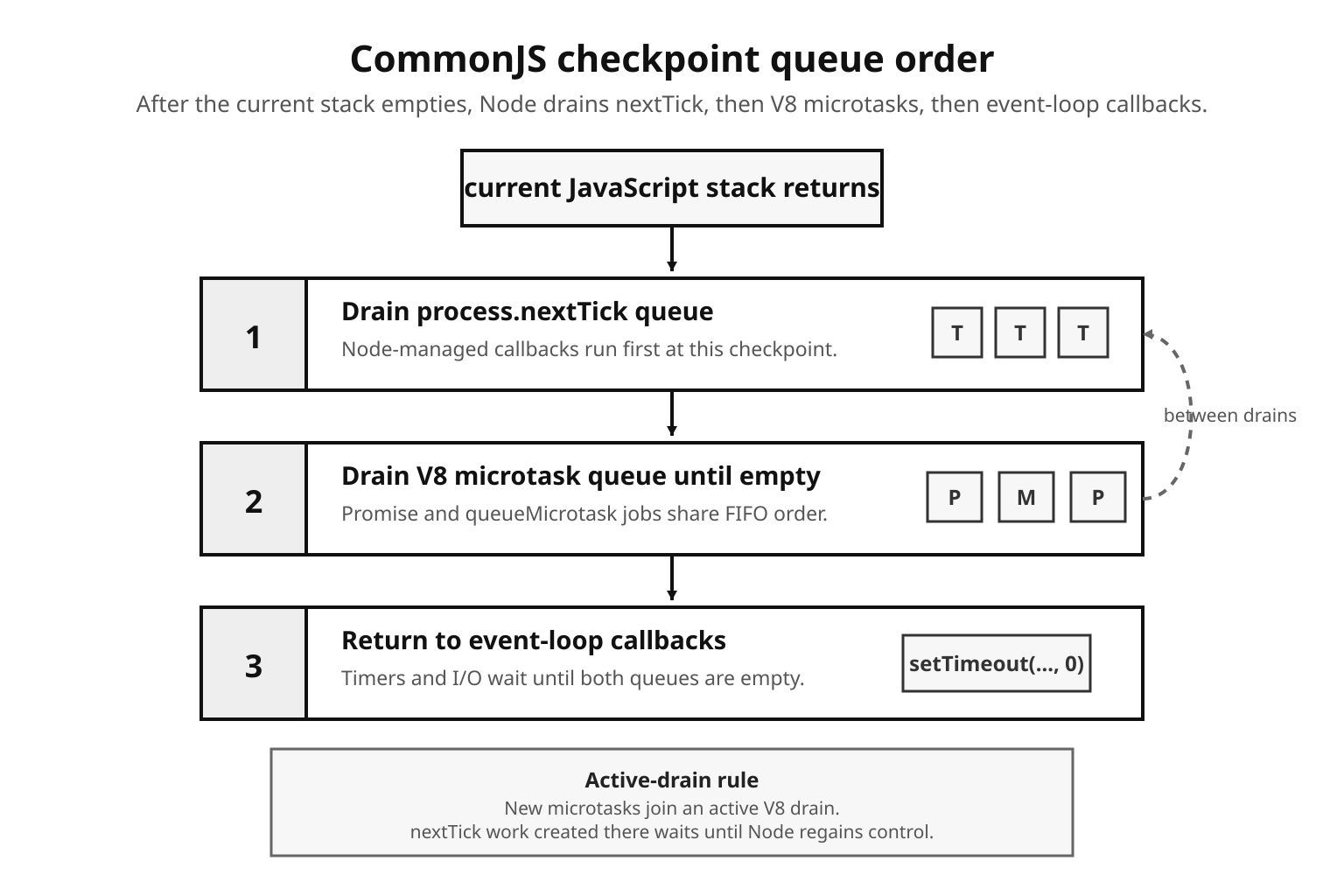
Figure 3 - At a CommonJS checkpoint, Node drains nextTick work and V8 microtasks before event-loop callbacks such as timers get their turn. Work queued during an active drain stays with that drain.
console.log("1");
setTimeout(() => console.log("2"), 0);
Promise.resolve().then(() => console.log("3"));
process.nextTick(() => console.log("4"));
console.log("5");In a CommonJS main script, the output is 1, 5, 4, 3, 2.
The synchronous lines run first. setTimeout() registers a libuv timer. Promise.resolve().then() enqueues a PromiseReactionJob in V8. process.nextTick() appends to Node's nextTick queue. The final console.log() still runs before any queued callback.
When the stack empties, Node enters a checkpoint. In this CommonJS context, it drains nextTick first, so 4 prints. Then it drains V8 microtasks, so 3 prints. Only after those queues are empty does the event loop move to expired timers and print 2.
Different active contexts can produce different output. ES module top-level evaluation already runs through the microtask machinery, so the same scheduling shape prints the promise line before the nextTick line. Code resumed after await has the same active-microtask caveat.
The table near the start of the chapter gives the short version. The examples below show where the difference appears.
Native callback return points also run checkpoints. When a libuv completion enters JavaScript and the callback returns, Node coordinates its nextTick queue, V8 microtask checkpoint, and rejection bookkeeping before moving back to more event-loop work. Internal function names can change across Node versions. The observable behavior is the checkpoint.
The rule that trips people up is this - nextTick has priority at CommonJS and native-callback checkpoints, but it does not interrupt an active V8 microtask drain.
If a .then() handler calls process.nextTick(), that nextTick callback waits until V8 finishes the current microtask queue. Then control returns to Node, and Node can drain nextTick.
Promise.resolve().then(() => {
process.nextTick(() => console.log("tick"));
queueMicrotask(() => console.log("micro"));
});The queueMicrotask() callback runs before the process.nextTick() callback created inside the promise handler. V8 is already draining microtasks, so the new microtask joins the active drain. The nextTick callback waits for control to return to Node.
Reverse the creation site and the order changes -
process.nextTick(() => {
Promise.resolve().then(() => console.log("promise"));
process.nextTick(() => console.log("tick"));
});The nested nextTick runs before the promise handler. Node is already draining the nextTick queue, and new nextTick entries stay in that queue until it empties. After that, Node runs V8 microtasks.
Use this ordering knowledge mainly for debugging. Code that depends on nested nextTick-versus-promise behavior is hard to review. But when a log line appears one step earlier than expected, the active queue usually explains it.
queueMicrotask(fn) schedules directly into V8's microtask queue without creating a promise for the scheduling operation. In Node v24, process.nextTick() is documented as Legacy, and queueMicrotask() is the better default for most userland deferral that does not need Node-specific nextTick priority.
process.nextTick(() => console.log("nextTick"));
queueMicrotask(() => console.log("microtask"));
Promise.resolve().then(() => console.log("promise"));In a CommonJS main script, the output is nextTick, microtask, promise.
queueMicrotask() and promise reactions share FIFO ordering inside V8's queue. The nextTick queue runs ahead of both at that checkpoint.
Starvation
Microtask draining is exhaustive. That means Node keeps draining the microtask queue until it is empty.
That behavior is useful for predictable promise ordering, but it also creates a failure mode. If each microtask schedules another microtask, the event loop may not get back to timers, I/O, check callbacks, or close callbacks.
let count = 0;
function flood() {
if (++count === 100_000) return;
Promise.resolve().then(flood);
}
flood();Each handler queues another handler until the guard stops it. While that chain is active, JavaScript keeps running inside the checkpoint. Timers stay pending. I/O completions wait. The process uses CPU but makes no event-loop progress.
Remove the guard, and the loop can starve the process indefinitely.
process.nextTick() can create the same failure mode. It has caused plenty of production pain because people often used it as a yield primitive. It yields from the current stack, but it still runs ahead of event-loop phases.
Do not rely on a runtime queue-depth guard to save recursive promise or nextTick scheduling. Bounded recursion is fine. Unbounded recursion starves the loop.
Use setImmediate() when a large CPU-light batch needs to let the event loop return to phase work between chunks. setImmediate() runs in the check phase, and an immediate queued from inside an immediate runs on a later event-loop iteration.
Ready timers and I/O still depend on phase timing, but microtask recursion gives them no chance until the queue empties.
The tradeoff is overhead versus latency. Microtasks are cheap and tightly ordered. setImmediate() costs more and gives other work a chance to run. For request-serving code, bounded latency for unrelated sockets is usually more valuable than finishing one batch through a microtask chain as fast as possible.
Batch size is the control value. Process a few hundred items, schedule the next chunk with setImmediate(), and keep request latency bounded. Process the whole batch through promise recursion, and every socket that becomes readable during the batch waits behind your microtask chain.
The right batch size depends on item cost and latency budget. Measure it under load instead of copying a random constant.
Starting Work vs Observing Work
Promise APIs are easier to reason about when you separate two actions - starting work and observing the result.
Promise construction or function entry starts work. .then() observes completion. Those actions can happen at different times.
const p = readConfig();
doSomethingSync();
p.then(config => applyConfig(config));readConfig() decides when the file read, cache lookup, or network call begins. The later .then() only registers a reaction.
If readConfig() has already fulfilled by then, the reaction still goes through the microtask queue. If it is still pending, the reaction waits in the promise's internal list until settlement.
This difference shapes lazy APIs. A promise usually represents work that has already started. A function returning a promise can be lazy because work starts when the function is called. Passing a promise around passes an in-flight or already-settled operation. Passing a function around passes the ability to start the operation later.
const eager = fetchUser(id);
const lazy = () => fetchUser(id);eager begins immediately. lazy begins when called.
The scheduling rules after settlement stay the same, but the resource timing changes. Sockets open earlier, timers start earlier, and unhandled rejection tracking can begin before the consumer has attached handlers.
That is why retry loops, concurrency limiters, and deferred batches usually accept functions. They need to control when each promise-producing operation starts.
Promise handlers also run after synchronous cleanup in the current turn. That can be useful, and it can be surprising.
const p = Promise.resolve();
let closed = false;
p.then(() => console.log(closed));
closed = true;The handler prints true. The assignment runs before the microtask checkpoint.
If the handler needs the earlier value, capture it before scheduling the handler. Microtasks preserve ordering, but they do not freeze variables.
A small naming habit helps during reviews. Name promise-returning functions with verbs, and name promise values as values in progress.
loadUser() starts work. userPromise is a promise representing work already started.
The names cannot enforce timing, but they expose the difference where mistakes happen. A retry helper should receive () => loadUser() because it needs a fresh attempt each time. A renderer can receive userPromise because it only needs to observe the result.
The same start-versus-observe separation shows up during startup, retries, cache warmups, and request fan-out. Calling a promise-returning function can open sockets, start timers, or begin rejection tracking before the consumer is ready.
Errors and Rejections
Rejections move down the chain until something handles them.
Promise.reject(new Error("bad"))
.then(v => console.log("skipped"))
.then(v => console.log("also skipped"))
.catch(e => console.log(e.message)); // "bad"Fulfillment-only handlers are skipped. The rejection value passes through until .catch() receives it.
Inside .catch(), returning a normal value recovers. Throwing keeps the chain rejected. Returning a rejected promise also keeps the chain rejected.
Logging and re-throwing is common when one layer wants visibility and another layer owns the response -
someAsyncOp()
.catch(e => {
console.error("logged", e);
throw e;
})
.then(v => processResult(v))
.catch(e => sendErrorResponse(e));The first catch logs and throws. The second catch sees the same failure. If the first catch returned normally, the chain would continue with that returned value, often undefined.
throw inside a handler and return Promise.reject(error) both reject the promise returned by that handler's .then() call. Prefer throw inside synchronous handler bodies because it is shorter and easier to read. Promise.reject() fits helper functions or expression-heavy code that already returns promises.
fetchUser(id).then(user => {
if (!user.active) throw new Error("inactive");
return user;
});That behaves the same as returning Promise.reject(new Error("inactive")), with less noise.
Unhandled Rejections
Node reports rejected promises that do not have a rejection handler by the time its rejection check runs. In Node v24, the default --unhandled-rejections mode is throw. An unhandled rejection becomes an uncaught exception.
The flag also accepts warn, strict, and none, but production code should treat unhandled rejections as process-level bugs.
The detection starts in V8. When a promise rejects without a handler, V8 calls Node's promise rejection hook. Node records the promise and waits briefly before reporting. That gives the current turn a chance to attach a handler.
If a handler appears in time, Node records the handled transition instead of reporting it as unhandled. If the promise still has no handler, unhandledRejection fires on process, and the default throw mode turns that into a thrown exception.
That brief wait prevents valid code from being reported too early. A promise can reject, then receive a .catch() later in the same synchronous turn. A chain can also attach rejection handling through a later .then() call before Node finishes the checkpoint.
Two process events describe the lifecycle. unhandledRejection fires when Node decides the promise did not get a handler in time. rejectionHandled fires later if a handler appears after reporting.
The second event is diagnostic cleanup. It does not undo the first event. In throw mode, the process may already be going through uncaught-exception handling.
You can see the timing with process-level diagnostic handlers -
process.on("unhandledRejection", e => {
console.log("unhandled -", e.message);
});
process.on("rejectionHandled", () => {
console.log("handled later");
});
const p = Promise.reject(new Error("oops"));
setTimeout(() => {
p.catch(e => console.log("caught -", e.message));
}, 0);The setTimeout() callback runs after the microtask checkpoint and timer scheduling point. Node can report the rejection before the delayed catch attaches. Later, the catch causes a rejectionHandled event, but the original report already happened.
Without those process handlers, the same delayed-catch shape exits under Node v24's default throw mode before the timer-attached catch runs.
Attach rejection handlers in the same chain you create. End a floating promise with .catch() when it is intentionally detached. With async functions, use try/catch around awaited work or return the promise to a caller that will handle it.
promise.catch(() => {}) counts as handling. It also hides the failure. Sometimes that is intentional for best-effort telemetry or cache writes. Make that choice visible in code. Log enough context for debugging unless the failure is intentionally silent.
Library code should avoid setting global process.on("unhandledRejection") policy. Applications own that decision. A library can return promises, document rejection reasons, and attach internal catches for detached background work it starts itself. Process-level rejection policy belongs at the entry point, beside signal and exit handling.
util.promisify() and Callback APIs
Node still has many callback-shaped APIs, and many packages expose error-first callbacks. util.promisify(fn) wraps one of those functions and returns a promise-returning version.
const { readFile } = require("node:fs");
const { promisify } = require("node:util");
const readFileAsync = promisify(readFile);
readFileAsync(__filename, "utf8").then(text => {
console.log(text.includes("readFileAsync"));
});The wrapper calls the original function with your arguments and appends a generated callback. If that callback receives a truthy err, the promise rejects. Otherwise, the promise resolves with the success value.
Each wrapper call allocates a promise and a callback closure. For one file read, that cost is irrelevant. In busy library paths, those allocations can show up in heap profiles.
Binding also needs attention. promisify() calls the original function as a plain function unless you bind it first. Methods that depend on this need binding before wrapping.
const { promisify } = require("node:util");
const obj = {
value: 7,
read(cb) {
cb(null, this.value);
}
};
const readAsync = promisify(obj.read.bind(obj));Core functions usually avoid this problem because they take state through arguments or internal bindings. User-space classes often rely on this. A promisified unbound method can fail before it even reaches async work.
Some Node APIs return multiple callback success values. fs.read() receives (err, bytesRead, buffer). Node core uses internal metadata so promisified versions can resolve with an object such as { bytesRead, buffer } instead of dropping everything after the first success value.
Your own APIs can define util.promisify.custom for the same reason -
const { promisify } = require("node:util");
function myFn(cb) {
cb(null, "a", "b");
}
myFn[promisify.custom] = () => {
return Promise.resolve({ first: "a", second: "b" });
};
promisify(myFn)().then(console.log);Prefer promise-native Node APIs when they exist. require("node:fs/promises") avoids a userland util.promisify() wrapper and exposes promise behavior directly. The public API is cleaner, and the runtime does not need to route your code through a generated callback closure.
util.promisify() is still useful for third-party callback APIs and older internal modules. Treat it as an adapter at the boundary. Once data enters promise form, keep the rest of the code in one async style.
The reverse direction needs the same care. If a callback-based public API must stay for compatibility, keep the callback adapter thin and route into a promise-native implementation. Mixed internal styles duplicate error handling and make ordering harder to follow.
util.callbackify() adapts from promises back to callbacks. It calls a promise-returning function, attaches handlers, and routes fulfillment or rejection to an error-first callback. That adds the same promise reaction scheduling point. Callback consumers that expect exact timing may observe the extra microtask turn.
callbackify() has one odd case. Rejected falsy values get wrapped, because an error-first callback uses a truthy first argument to signal failure. Rejecting with null or undefined gives the callback a generated Error object with the original reason attached.
That is another reason to reject with real errors.
Cost Model
Every .then() creates a promise. Every settled promise with a dependent handler schedules a PromiseReactionJob. Every handler closure can keep outer variables alive until the chain releases them.
Those costs show up as allocations, queued jobs, retained closures, and async-stack metadata. They only need your attention when profiling shows they affect the workload.
Promise handlers always run asynchronously. Even this schedules fn in a microtask -
Promise.resolve(42).then(fn);That always-async behavior is part of the promise contract. It removes the mixed sync/async behavior that callback APIs can accidentally create. Cached results and I/O results use the same observation timing - current stack first, microtasks next.
Long chains create short-lived objects. Ten .then() calls produce ten intermediate promises and ten reaction jobs. Modern V8 optimizes common promise paths, but heap churn can still show up in code that builds huge numbers of tiny chains per second.
A callback-only internal path can allocate less in measured hot loops. Database drivers, parsers, schedulers, and transport libraries sometimes expose promises at the public API and use callbacks or internal request objects below that line. That is an implementation choice. It is not a reason to leak callback control flow into application code.
Most application code should keep promises. The readability and consistent error channel usually beat the allocation difference. Profile before replacing a promise chain with callback code. If promise allocation shows up in the profile, it may appear as young-generation churn, frequent minor GC, or promise-reaction frames in CPU profiles.
Memory retention is easier to miss. A chain like a.then(f1).then(f2).then(f3) creates intermediate promises that can die quickly after the next link settles. A handler closure can keep anything it captures from the outer scope.
A .finally() closure that captures a large buffer keeps that buffer reachable until the finally handler runs and the returned promise settles. A stored reference to a mid-chain promise can also keep related state alive longer than expected.
Here is the common retention bug -
function handle(req, big) {
return doWork(req.id).finally(() => {
metrics.observe(big.length);
});
}The finally closure keeps big alive until the chain settles. If big is a request body buffer and the operation waits on remote I/O, memory pressure climbs with concurrency.
Extract the small value before creating the closure -
function handle(req, big) {
const bytes = big.length;
return doWork(req.id).finally(() => {
metrics.observe(bytes);
});
}The behavior is the same, but less memory stays reachable.
Debugging has its own tradeoff. Async stack traces make rejected chains easier to investigate, but they can keep metadata around. Keep diagnostics useful by default, then change diagnostic settings only when a measured workload points at them.
Performance work starts with program shape, not syntax. A chain that serializes independent operations costs more than the promise mechanism itself. A detached promise with no handler creates failure ambiguity. A busy loop that builds millions of promises creates allocator pressure.
Fix those first. Then decide whether a lower-level callback path earns its complexity.
In production code, the defaults stay simple -
- Use promise-native Node APIs instead of promisifying core APIs.
- Attach
.catch()in the chain that creates detached work. - Prefer end-of-chain
.catch()over two-argument.then()for most code. - Use
throwinside handlers unless a helper already returns a promise. - Use
setImmediate()between large independent batches that must let I/O proceed. - Watch heap profiles for retained closures around large buffers or request objects.
- Treat
PromiseReactionJobhotspots as profiling data, not as a reason to rewrite clean code early.
Promise code is usually the right surface. The sharp parts are scheduling context, rejection ownership, and retained state. Those are runtime behaviors, so make them visible in the way you structure the code.